
Introduction The field of computer vision and image processing has experienced unprecedented growth in recent years, significantly impacting various industries, from autonomous vehicles to medical diagnostics. Central to this evolution is OpenCV, an open-source computer vision library that has garnered over 1.5 billion downloads globally. The upcoming OpenCV-SID Conference on Computer Vision & AI (OSCCA), scheduled for May 4th, 2026, in Los Angeles, promises to be a pivotal event for professionals in this domain. Notably, Gary Bradski, the founder of OpenCV, will be delivering a keynote address, providing attendees with insights rooted in decades of expertise in artificial intelligence (AI), robotics, and machine learning. Primary Objectives of the Conference The primary goal of the OSCCA is to foster knowledge exchange and collaboration among experts in computer vision and AI. By convening leaders from industry giants such as Ultralytics and Disney Research Imagineering, the conference aims to illuminate the latest advancements and applications in the field. Attendees will gain a unique opportunity to engage with influential figures and learn firsthand about innovative technologies that are shaping the future of computer vision. Advantages of Attending OSCCA Networking Opportunities: Attendees will have the chance to connect with top-tier professionals and organizations, facilitating partnerships and collaborations that can accelerate research and development in computer vision. Access to Cutting-edge Research: The conference will showcase groundbreaking work from various sectors, enabling participants to stay abreast of the latest trends and findings relevant to their specific interests. Free Access to the AI Pavilion: Your OSCCA ticket includes passes to the Display Week Exhibition Hall, featuring over 200 exhibitors. This provides invaluable exposure to emerging technologies and companies driving innovation in AI. Insights from Industry Pioneers: The keynote address by Gary Bradski offers a rare opportunity to learn from a pioneer who has significantly shaped the landscape of computer vision and AI. Caveats and Limitations While the benefits of attending OSCCA are substantial, it is essential to acknowledge potential limitations. For instance, the sheer volume of information presented in a single day may overwhelm attendees, necessitating careful selection of sessions to maximize value. Additionally, participants should come prepared with specific questions or areas of interest to ensure they engage meaningfully with speakers and peers. Future Implications of AI in Computer Vision The implications of advancements in AI for computer vision are profound. As AI technologies continue to evolve, their integration into computer vision applications is likely to enhance accuracy, efficiency, and scalability. The ongoing development of machine learning algorithms will enable more sophisticated image analysis, driving innovations in fields such as autonomous navigation, healthcare diagnostics, and smart city infrastructure. Moreover, as the conference highlights, collaboration among industry leaders will be crucial in addressing ethical and practical challenges, ensuring that the evolution of computer vision aligns with societal needs and values. Conclusion In summary, the OSCCA conference represents a critical juncture for professionals in the computer vision and image processing domains. With the opportunity to learn from industry leaders, network with peers, and gain insights into future trends, attending this event could significantly enhance a participant’s knowledge and influence within the field. As the landscape of computer vision continues to evolve, engaging with these developments at OSCCA is an invaluable step towards staying at the forefront of this dynamic industry. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
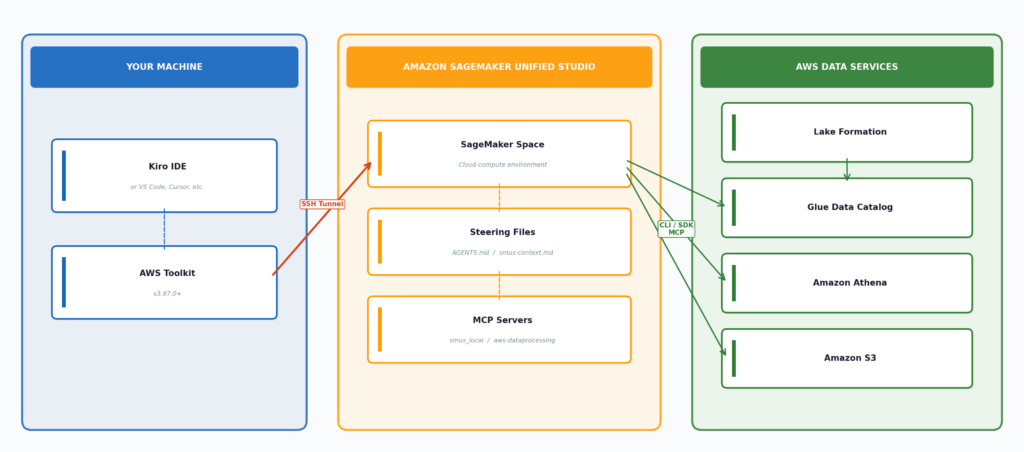
Context: AI-Assisted Data Development in Big Data Engineering In the rapidly evolving landscape of software development, AI coding assistants are emerging as transformative tools. However, data engineering presents a unique set of challenges that differ significantly from traditional software development. These challenges include governed data access, shared compute environments, and compliance controls that must be consistently enforced. The essential question arises: how can organizations harness the power of AI-assisted development within such a governed data environment? The integration of the AWS Toolkit for Visual Studio Code with tools like Kiro, VS Code, and Cursor provides a solution, facilitating direct connections to Amazon SageMaker Unified Studio. This enables developers to leverage AI-assisted development while ensuring compliance with data governance and project permissions. By connecting an editor to a SageMaker Unified Studio Space—essentially a cloud-based compute environment—developers gain the benefits of AI-assisted development while SageMaker manages essential aspects such as data governance and compute resources. Additionally, SageMaker Unified Studio automatically generates steering files (such as AGENTS.md) that equip the AI assistant with contextual knowledge about the project environment, ensuring an informed and effective interaction from the outset. Main Goal and Achievement The primary objective of this integration is to streamline the data development process by allowing data engineers to utilize natural language queries to explore and analyze data within a governed environment. This is achieved by establishing a seamless connection between Kiro and Amazon SageMaker Unified Studio, enabling the AI assistant to access project-specific data and configurations without requiring extensive manual setup. By leveraging this integration, data engineers can focus on deriving insights rather than navigating the complexities of data governance and access controls. Advantages of AI-Assisted Development Enhanced Productivity: The integration facilitates rapid data exploration using natural language prompts, which streamlines the workflow for data engineers. For example, data engineers can simply ask, “Show my databases and the tables I have access to,” thereby eliminating the need to write complex queries manually. Automatic Context Generation: Through the automatic generation of steering files, the AI assistant is pre-equipped with relevant information about the data and environment, enhancing its effectiveness from the first interaction. This reduces the time spent on configuration and setup, allowing for faster project initiation. Seamless Compliance: By utilizing SageMaker’s governance features, data engineers can ensure that all data access and processing adhere to organizational policies. This integration ensures compliance without compromising on the innovative capabilities of AI. Dynamic Query Capabilities: The integration supports various data services, allowing data engineers to dynamically query AWS Glue Data Catalog and execute SQL queries using Amazon Athena. This flexibility empowers engineers to perform complex data analyses efficiently. Caveats and Limitations While the advantages are substantial, there are important caveats to consider. The AI assistant’s output is inherently non-deterministic, meaning that responses can vary with each session, even when using the same prompt. This variability can lead to inconsistencies in code generation and tool choices, necessitating careful validation of outputs. Additionally, the reliance on natural language processing may inadvertently lead to misinterpretations if prompts are not clearly articulated. Future Implications of AI in Data Engineering The integration of AI technologies into data engineering is poised to redefine the field significantly. As AI models become more sophisticated, we can anticipate improvements in their contextual understanding and execution capabilities, reducing the need for manual intervention. This evolution could lead to a paradigm where data engineers spend less time on repetitive tasks and more time on strategic initiatives, such as developing new data products and optimizing workflows. Furthermore, as organizations increasingly adopt AI-driven tools, the demand for skilled professionals who can effectively leverage these technologies will undoubtedly rise, emphasizing the need for continuous learning and adaptation in the workforce. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The integration of generative AI models and robotics represents a pivotal advancement in the field of artificial intelligence, particularly for Generative AI Scientists. The collaboration between the Hugging Face Hub and robotic hardware via tools like Strands Agents and LeRobot facilitates a streamlined process for training and deploying robotic systems. This blog post will elucidate the main objectives of this integration, the benefits it offers, and the future implications for AI development. Main Goal of Integration The primary goal of the integration between Hugging Face and Strands Agents is to create a cohesive workflow that allows for seamless transition from simulation to real-world application. This involves utilizing generative AI models to train robotic systems using data captured from both simulated environments and actual hardware. By leveraging AgentTools from Strands, developers can construct agents that operate in a unified manner across different platforms, effectively bridging the gap between machine learning and robotics. Advantages of the Integration Unified Framework: The integration provides a single framework whereby datasets can be easily shared and utilized across both simulated and physical robots. This eliminates the need for complex conversions, enhancing productivity. Enhanced Flexibility: Developers can switch between simulation and real-world applications without altering the underlying code base. This flexibility allows for rapid prototyping and iterative testing. Robust Dataset Management: The use of a consistent dataset format across both environments simplifies data management, making it easier to train and fine-tune models. Scalability: The architecture supports the deployment of multiple robots operating simultaneously, which is particularly beneficial for applications requiring fleet coordination. Ease of Use: The integration facilitates a user-friendly experience for developers, enabling them to deploy AI models with minimal technical barriers, thus broadening accessibility to AI-driven robotics. Caveats and Limitations While the integration offers numerous advantages, it is essential to acknowledge certain limitations. The reliance on high-quality datasets is crucial; poor data quality can lead to suboptimal training outcomes. Additionally, the hardware requirements for real-world applications, such as GPU availability and calibration of robotic systems, may present challenges for some users. Security considerations, including prompt injection risks and the need for proper authentication in mesh networks, must also be carefully managed to ensure safe operation. Future Implications The advancements in AI and robotics as facilitated by this integration are likely to have profound implications for the future of technology. As generative AI models continue to evolve, we can expect a significant increase in the capabilities of robotic systems, allowing them to perform more complex tasks autonomously. This will lead to broader applications across various industries, including healthcare, manufacturing, and logistics, where robotics can enhance operational efficiency and effectiveness. Furthermore, as AI models become more embedded in physical applications, ethical considerations surrounding autonomy and decision-making in robotics will gain prominence, necessitating ongoing discourse among developers, researchers, and policymakers. Conclusion The integration of generative AI models with robotic systems via the Strands Agents and LeRobot framework represents a significant leap forward in the capabilities of AI. By fostering a unified approach to training and deploying robots, this collaboration not only enhances operational efficiency but also opens new avenues for future technological advancements. As the field continues to evolve, the synergy between AI and robotics will undoubtedly shape the landscape of automation and intelligent systems. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction In the field of Applied Machine Learning, data cleaning and preparation are critical components that can significantly influence the efficiency of a data scientist’s workflow. It is estimated that data cleaning occupies up to 80% of a data scientist’s daily activities. Given that Pandas is the predominant library for data manipulation in Python, the proficiency in utilizing this tool is paramount for transitioning from raw data to actionable insights. As such, the ability to enhance data preparation processes not only streamlines workflows but also allows more time for modeling and analysis, ultimately facilitating better communication of insights. Despite the importance of effective data handling, many practitioners tend to rely on outdated coding practices that resemble conventional Python looping structures or use in-place mutations. These methods can lead to several challenges, including the infamous SettingWithCopyWarning, excessive memory usage due to redundant copies, and decreased execution speed due to a lack of vectorization. To address these challenges, it is essential for practitioners to adopt idiomatic Pandas design patterns, which can significantly enhance the efficacy of data cleaning and preparation tasks. Main Goal and Achievements The primary objective outlined in the original post is to promote efficient data cleaning and preparation in Pandas through the adoption of three key techniques: declarative method chaining, memory and speed optimization via categoricals and vectorized string accessors, and group-aware imputation using the .transform() method. Achieving this goal requires a shift from basic syntax to more advanced, idiomatic practices that allow for cleaner and more efficient code. Advantages of Efficient Data Cleaning Techniques Declarative Method Chaining: This technique allows for a sequential application of operations without in-place mutations, thereby reducing the risk of triggering warnings and improving code readability. By using methods like .assign(), .query(), and .pipe(), practitioners can create pipelines that are easier to debug and maintain. Memory and Speed Optimization: Converting low-cardinality categorical data into the category datatype and utilizing vectorized string methods can lead to significant reductions in memory usage and execution time. This optimization enables large datasets to be handled more efficiently, thereby enhancing the overall performance of data manipulation tasks. Group-Aware Imputation with .transform(): This method bypasses the inefficiencies of custom looping structures by allowing Pandas to calculate group-level statistics and align results back to the original DataFrame. This approach not only enhances speed but also maintains accuracy in handling missing values. While these advantages offer substantial improvements, it is essential to recognize that there are limitations. For instance, while categorical transformations can be beneficial for low-cardinality data, they may not provide memory savings in cases of high-cardinality text. Practitioners should, therefore, assess their dataset characteristics before applying these techniques. Future Implications of AI Developments As advancements in artificial intelligence continue to evolve, the landscape of data preparation is likely to undergo transformative changes. Future developments may introduce more sophisticated automated tools that can handle data cleaning and preparation with minimal human intervention. This could potentially reduce the time spent on these tasks, allowing data scientists to focus more on complex modeling and analysis. Additionally, the integration of AI into data pipelines may lead to enhanced predictive capabilities, enabling practitioners to derive insights from datasets that were previously deemed too cumbersome to process efficiently. In conclusion, adopting advanced techniques for data cleaning and preparation in Pandas not only improves workflow efficiency but also enhances the overall quality of machine learning models. By embracing these practices, practitioners can better prepare themselves for the future of data science in an increasingly AI-driven environment. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction In the realm of data science, the processing and analysis of time-series data is of paramount importance, particularly in applications involving sensor readings and various metrics that evolve over time. Traditional machine learning frameworks, such as scikit-learn, are often ill-suited for these types of datasets due to their inherent structural complexities—namely seasonality, trends, temporal ordering, and the dependency of future values on historical data. This is where sktime, a Python library specifically designed for time-series analysis, comes into play, offering a scikit-learn-style API tailored for the unique requirements of time-series data. Main Goals of Time-Series Modeling The primary objective of utilizing sktime is to effectively build and evaluate machine learning models that can accurately forecast future values based on past data. Specifically, this article elucidates the methodology for forecasting temperature readings from an industrial HVAC sensor, demonstrating how sktime can streamline the tasks of data preprocessing, model fitting, and evaluation. By leveraging the capabilities of sktime, users can enhance predictive accuracy, improve model interpretability, and efficiently handle the complexities of time-series data. Advantages of Using sktime for Time-Series Analysis Specialized Data Structures: sktime provides tailored data containers such as Series, Panel, and Hierarchical formats that are specifically designed to accommodate the sequential and temporal nature of time-series data. Chronological Data Handling: The library emphasizes the importance of maintaining chronological integrity when splitting datasets for training and testing, thus preventing data leakage and enhancing model validity. Flexible Forecasting Horizons: Users can define absolute or relative forecasting horizons, enabling adaptable modeling strategies that cater to specific forecasting needs. Streamlined Pipelines: sktime facilitates the construction of preprocessing and forecasting pipelines that allow for systematic handling of missing values, trends, and seasonality, thereby ensuring robust model performance. Model Evaluation Metrics: The integration of standard evaluation metrics, such as Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE), empowers users to quantitatively assess model performance and make informed adjustments. Caveats and Limitations While sktime offers a robust framework for time-series analysis, several limitations warrant consideration. The library’s efficacy is contingent upon the quality and granularity of the input data; poor-quality data can lead to inaccurate forecasts. Additionally, sktime’s reliance on the temporal structure of data may impose constraints when applied to datasets lacking consistent time intervals. Users should also be cognizant of the computational resources required for processing large datasets, as the complexity of models can lead to increased processing times. Future Implications of AI Developments in Time-Series Analysis The rapid advancements in artificial intelligence (AI) and machine learning technologies are poised to significantly impact the field of time-series analysis. Enhanced algorithms, particularly those incorporating deep learning techniques, may yield even greater predictive capabilities. Moreover, as AI continues to evolve, the integration of natural language processing (NLP) within time-series frameworks could lead to richer contextual insights, enabling analysts to derive more nuanced interpretations from their data. As the demand for accurate forecasting grows across various industries, ongoing developments in this field will likely result in increasingly sophisticated tools and methodologies, ultimately driving better decision-making processes. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context: The Banned Book Library Project The Banned Book Library project exemplifies an innovative approach to information dissemination in environments where access to specific literature is restricted. By repurposing WiFi-enabled LED light bulbs as a means to host digital copies of banned books, the initiative reflects a broader concern regarding censorship and the importance of information accessibility. The project leverages technology in a manner reminiscent of a cyberpunk narrative, creating discreet, open-access points for knowledge sharing within communities. Main Goal and Achievement Methodology The principal objective of the Banned Book Library project is to provide a covert platform for accessing literature that may be banned in certain regions. This is achieved by modifying smart light bulbs to function as WiFi access points, allowing individuals to connect and access a library of digital books. The project underscores the importance of innovative thinking in utilizing existing technologies for socio-political purposes, demonstrating how everyday devices can facilitate the preservation and sharing of information in a restricted context. Advantages of the Banned Book Library Initiative Increased Accessibility: By transforming light bulbs into information access points, the project enhances the availability of banned literature to individuals who might otherwise lack access. Cost-Effectiveness: The use of inexpensive smart bulbs makes the project financially viable, allowing for multiple installations without significant expense. Community Engagement: The project encourages local participation in knowledge sharing, fostering a community-oriented approach to combating censorship. Technological Innovation: It showcases the potential of repurposing existing technology for new applications, highlighting the versatility of smart devices in addressing social issues. Environmental Awareness: Utilizing LED bulbs not only provides energy-efficient solutions but also promotes awareness about sustainable practices in technology use. Limitations and Caveats Despite its advantages, the Banned Book Library project faces notable limitations. The primary concern revolves around storage capacity, as the firmware and the hosted literature must all fit within the device’s 4MB limit. This constraint restricts the number and diversity of books that can be made available. Additionally, modifying light bulbs requires technical expertise, which may deter some potential participants from engaging with the project. Furthermore, the security of the WiFi access points may pose risks, as they could potentially expose sensitive user data. Future Implications and the Impact of AI Developments Looking ahead, the intersection of AI and technology will likely enhance projects like the Banned Book Library. Future advancements in AI could lead to improved methods for data compression, enabling more extensive libraries to be hosted within the limited storage of such devices. Additionally, AI-driven algorithms could facilitate more efficient management of digital libraries, allowing for better cataloging, retrieval, and user recommendations based on individual preferences. Moreover, the integration of AI technologies in the development of secure communication protocols could mitigate some of the security concerns associated with public access points. As society continues to grapple with issues of censorship and information access, projects like the Banned Book Library may serve as vital precedents for leveraging technology to foster knowledge sharing in constrained environments. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction Recent investigations into the nature of consciousness have sparked intriguing discussions among scientists and philosophers, specifically regarding whether non-human entities such as honey bees and artificial intelligence (AI) like ChatGPT could possess consciousness. This inquiry not only challenges our understanding of sentience but also raises ethical considerations regarding our interactions with other beings, be they biological or mechanical. The current discourse suggests a nuanced exploration of consciousness that balances skepticism with the precautionary principle, urging researchers to consider the implications of their findings on moral and ethical grounds. The Main Goal The primary objective of the ongoing research is to develop robust methodologies for assessing consciousness across various entities, including animals and AI systems. By proposing new frameworks for evaluation, researchers aim to expand our ethical considerations regarding sentience. This goal can be achieved through interdisciplinary collaboration that combines insights from cognitive science, neuroscience, and philosophy to establish a more comprehensive understanding of consciousness. Advantages of Expanding Consciousness Research Ethical Implications: Expanding the definition of consciousness influences our moral responsibilities toward different species and AI. Acknowledging potential consciousness in non-human entities compels us to reconsider our ethical frameworks, as highlighted by the New York Declaration on Animal Consciousness. Enhanced Understanding of Consciousness: By exploring the mechanisms that underpin consciousness rather than merely behavioral responses, researchers can create a more nuanced understanding of sentience. This approach promotes scientific rigor and helps avoid misconceptions associated with superficial behaviors. Interdisciplinary Collaboration: The convergence of neuroscience, cognitive science, and AI research fosters a richer dialogue about consciousness, which can lead to innovative approaches in both AI design and animal welfare. Future AI Developments: As AI technologies advance, understanding the potential for machine consciousness may guide ethical AI development, ensuring that emerging systems align with moral considerations and societal values. Limitations and Caveats While the exploration of consciousness in both animals and AI presents numerous advantages, several limitations must be acknowledged. For instance, the current methodologies primarily focus on observable behavior, which may not accurately reflect underlying conscious experiences. Additionally, the philosophical debate surrounding the nature of consciousness remains unresolved, complicating the establishment of universally accepted criteria for consciousness. These challenges necessitate ongoing dialogue and research to refine our understanding of the subject. Future Implications The implications of advancements in AI and consciousness research are profound. As AI systems become increasingly sophisticated, understanding the potential for machine consciousness could lead to significant ethical questions regarding rights and responsibilities. Furthermore, as researchers develop more nuanced frameworks for assessing consciousness, they may discover previously unrecognized forms of sentience, prompting a reevaluation of our moral obligations toward various forms of life and intelligence. The future trajectory of AI research and innovation will likely be shaped by these evolving understandings, ultimately influencing the ethical landscape in which we operate. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The realm of computer vision has experienced significant evolution over the past decades, with OpenCV emerging as a cornerstone for various applications ranging from robotics to medical imaging. The recent launch of OpenCV 5 marks a pivotal moment in this journey, introducing a comprehensive modernization of the library that promises to enhance the capabilities and accessibility of computer vision technologies. This blog post provides an overview of the implications of OpenCV 5 for vision scientists and the broader field of image processing. Context of OpenCV 5 in Computer Vision OpenCV, a widely utilized library with over a million daily installations, serves as a foundational tool for computer vision research and development. The release of OpenCV 5 aims to address the growing complexity of modern computer vision applications that integrate classical vision techniques with deep learning methods, requiring robust support for diverse hardware and software environments. Vision scientists, who rely on these tools, stand to benefit significantly from the enhancements offered in this latest version. Main Goals of OpenCV 5 The primary goal of OpenCV 5 is to modernize the library’s architecture while improving performance and usability. This objective is achieved through several key innovations: Enhanced DNN Engine: A complete overhaul of the Deep Neural Network (DNN) engine to support over 80% of ONNX operators, enabling better model integration and execution. Improved Language Support: Refreshing Python bindings and the introduction of named arguments for easier code comprehension and usage. Robust Hardware Acceleration: A redesigned Hardware Acceleration Layer (HAL) that permits seamless integration of optimized kernels across various hardware platforms. Expanded 3D Vision Capabilities: Enhanced tools for 3D vision, including improved camera calibration and visualization techniques. Advantages of OpenCV 5 The modernization of OpenCV 5 brings a multitude of advantages that hold particular significance for vision scientists: Increased Model Compatibility: The new DNN engine supports a broader array of models, reducing instances where developers encounter compatibility issues when loading modern machine learning models. Performance Improvements: Benchmarks indicate that OpenCV 5’s DNN engine can outperform established alternatives like ONNX Runtime, with speed increases of up to 36.6% for specific models. Cleaner API: The streamlined API reduces friction for developers, facilitating faster development cycles and easier debugging. Support for Advanced Features: The introduction of features such as dynamic shape handling and advanced tensor types enhances the library’s capability to handle complex models and data types. Limitations and Caveats However, it is essential to acknowledge certain limitations associated with OpenCV 5: CPU-Only DNN Engine: As of the current version, the new DNN engine supports CPU operations only, limiting the immediate applicability for high-performance GPU workloads. Potential for Breaking Changes: The transition to a new engine may introduce compatibility challenges for existing codebases, demanding careful testing during upgrades. Future Implications of AI Developments The advancements in OpenCV 5 not only represent a technological leap but also set the stage for future developments in computer vision. As artificial intelligence continues to evolve, the integration of sophisticated models and techniques into OpenCV will likely become more pronounced. Vision scientists can anticipate further enhancements in model efficiency, real-time processing capabilities, and the incorporation of emerging paradigms such as large language models (LLMs) within the computer vision framework. These developments will expand the scope of applications, facilitating innovations in fields like autonomous systems, augmented reality (AR), and beyond. Conclusion OpenCV 5 stands as a landmark release, providing a modernized infrastructure that enhances the functionality and usability of computer vision applications. By addressing the pain points of previous iterations and anticipating the needs of future applications, OpenCV 5 establishes a robust foundation for vision scientists aiming to leverage advanced image processing techniques. As the landscape of AI and computer vision continues to evolve, OpenCV 5 positions itself as a pivotal tool in the ongoing quest for innovation in this field. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
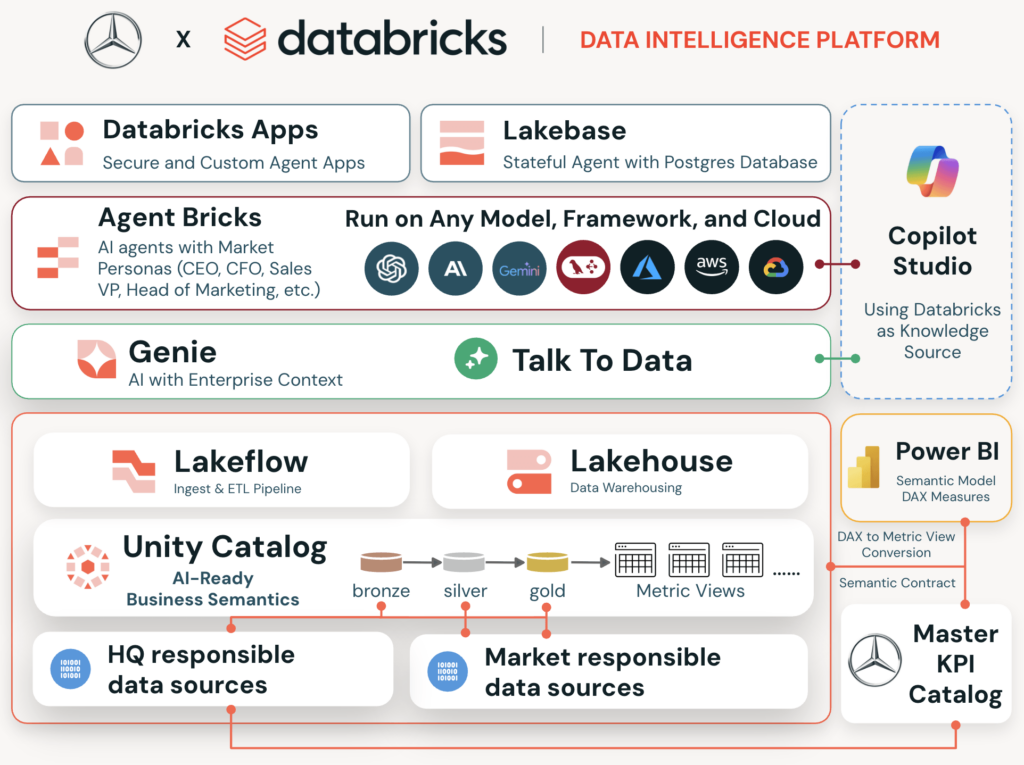
Context and Relevance in Big Data Engineering The demand for advanced data interaction capabilities, such as “Talk to Data,” is escalating across various industries. This trend underscores the necessity of a robust semantic foundation to facilitate reliable AI-driven responses. When AI systems leverage well-governed business logic rather than relying on convoluted schemas or disparate dashboards, the quality of answers improves significantly. Consistent key performance indicator (KPI) definitions, aligned business logic, and clearly defined joins and aggregations empower executives with the actionable insights they require. Mercedes-Benz Korea, in collaboration with Databricks, recognized this imperative and strategically expanded its analytics framework to incorporate a governed semantic layer suitable for enterprise AI applications. By facilitating access to KPI logic through platforms like Unity Catalog Business Semantics and Power BI, Mercedes-Benz Korea has pioneered a unified architecture that integrates data, semantics, and agentic AI. The insights gleaned from this initiative serve as a valuable blueprint for other markets within the Mercedes-Benz ecosystem. Main Objective and Its Achievement The primary goal of the “Talk to Data” initiative at Mercedes-Benz Korea was to establish an AI-ready, unified semantic foundation that could seamlessly support both business intelligence (BI) reporting and AI functionalities. This objective is achieved by ensuring that all data products are governed under consistent business definitions, thereby enhancing the reliability of AI outputs. This initiative was not merely about transitioning from Power BI but involved a comprehensive strategy to consolidate business logic across various platforms. By creating a single source of truth within the Unity Catalog, the organization aims to facilitate consistent AI responses across different scenarios, thereby streamlining the decision-making process. Advantages of a Unified Semantic Architecture Enhanced Consistency: By establishing a single source of truth, Mercedes-Benz Korea ensures that AI outputs align with established business definitions, thereby minimizing discrepancies in reporting across platforms. Improved Decision-Making: Executives benefit from explainable answers derived from a governed semantic foundation, enabling informed decision-making based on reliable data. Streamlined Data Access: The integration of KPI logic in Unity Catalog facilitates direct access for both BI tools and AI agents, leading to faster and more accurate responses to business queries. Efficiency in Development: The automated DAX-to-Metric-View transpiler significantly reduces the manual effort required for data migration, thereby expediting the onboarding of KPIs into the semantic layer. Future-Proofing Analytics: The architecture is designed to evolve towards agentic AI capabilities, allowing for the adaptation of governance structures as AI technologies progress. However, it is essential to recognize that the implementation of a unified semantic architecture requires meticulous planning and may pose challenges during the initial phases, particularly in terms of aligning existing data structures with new governance protocols. Future Implications of AI Developments The advancements in AI are set to transform the landscape of data engineering. As AI technologies become increasingly sophisticated, the need for well-defined semantic layers will intensify. Organizations will increasingly rely on AI to deliver contextual insights that are both accurate and timely, necessitating a robust infrastructure that can support these demands. Furthermore, as businesses adopt AI-driven analytics, the role of data engineers will evolve to encompass not only data management but also the curation of semantic frameworks that facilitate AI interactions. The implications of these developments will likely include enhanced collaboration between data scientists and engineers, driving innovation in AI applications across various sectors. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The advent of cloud gaming technologies such as GeForce NOW represents a significant evolution in the gaming industry, especially for PC gamers who often face hardware limitations and lengthy download times. Recently, GeForce NOW initiated a summer sale, offering substantial discounts on membership plans. This development underscores the increasing accessibility of high-performance gaming through cloud solutions, which can be particularly advantageous for professionals and enthusiasts in the field of Generative AI models and applications. Understanding the Main Goal The primary objective of GeForce NOW’s summer sale is to encourage gamers to upgrade their memberships, thereby providing them with enhanced cloud gaming experiences. By removing barriers such as hardware requirements and lengthy downloads, GeForce NOW allows users to engage in gaming with greater ease and accessibility. This goal can be achieved through the promotion of cost-effective membership options, which enhance the overall gaming experience while delivering the latest technology and game releases. Advantages of Cloud Gaming Instant Access to Games: Cloud gaming enables immediate access to a wide array of games without the need for extensive installations. This is particularly beneficial for gamers who wish to maximize their playtime. High Performance without Hardware Upgrades: Users can leverage the power of high-performance NVIDIA GPUs hosted in the cloud, eliminating the need for costly hardware upgrades. This is especially relevant for professionals in the AI field who may require robust computing power for their projects. Cross-Device Compatibility: The ability to play games on laptops, tablets, and phones enhances flexibility, allowing users to game on devices they already own. This feature is critical for GenAI scientists who may want to test algorithms or models during breaks or while traveling. Continuous Updates and Improvements: Regular platform upgrades ensure that members benefit from the latest technological advancements, extending the lifespan of gaming devices and enhancing user experience. Considerations and Limitations While the advantages of cloud gaming are compelling, potential caveats include reliance on a stable internet connection and potential latency issues. In regions with limited bandwidth, the gaming experience may be compromised, necessitating consideration of individual user circumstances before migration to cloud services. Additionally, ongoing membership costs may accumulate over time, which could be a concern for budget-conscious gamers. Future Implications of AI Developments The integration of artificial intelligence within cloud gaming environments is likely to shape the future of both gaming and Generative AI applications. As AI continues to evolve, we can anticipate more sophisticated algorithms that enhance game performance, optimize server loads, and improve user experience through personalized gaming environments. Moreover, the growing intersection of AI and gaming will likely foster innovative applications in machine learning and data analysis, providing further opportunities for GenAI scientists to explore and implement their research within interactive platforms. Conclusion In summary, the summer sale of GeForce NOW not only highlights the evolution of cloud gaming but also emphasizes its relevance for users in the Generative AI domain. By offering cost-effective access to high-performance gaming, GeForce NOW facilitates a seamless gaming experience that aligns with the needs of modern users. As advancements in AI technology continue to permeate the gaming industry, the implications for cloud gaming and its integration with Generative AI will undoubtedly expand, presenting new opportunities for innovation and engagement. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here