
Contextualizing the Role of Agentic AI in Workflow Management Agentic AI represents a transformative force in the realm of workflow management and automation. Its ability to not only automate isolated tasks but also to manage and coordinate overarching workflows is pivotal for contemporary business environments. This capability allows for a synergistic collaboration between humans and AI agents, enhancing productivity and operational efficiency. However, the deployment of such technologies is fraught with challenges, primarily due to the inherent risks associated with automated decision-making processes. Consequently, organizations must cultivate a robust confidence in the ability of these agents to perform tasks reliably and securely. Main Goal: Enhancing Trust in AI Agents The central objective articulated in the original discourse is to bolster confidence in agentic AI systems, thereby enabling organizations to delegate responsibilities effectively. Achieving this goal necessitates a two-pronged approach: developing more sophisticated reasoning capabilities within the agents and ensuring the provision of sufficient business context to facilitate informed decision-making. As technology teams gain experience with these systems, it is anticipated that confidence levels will rise correspondingly, thereby fostering broader acceptance and integration of agentic AI into business operations. Advantages of Agentic AI in Business Workflows Increased Efficiency: Technology experts assert that agentic AI can significantly streamline processes, allowing teams to focus on higher-level strategic initiatives rather than mundane tasks. Enhanced Decision-Making: The integration of AI agents into complex workflows can facilitate better decision-making by providing data-driven insights and automating routine judgments. Improved Trust in Data Integrity: Areas such as data quality monitoring and anomaly detection benefit from agentic interventions, ensuring that decisions are based on accurate and reliable data. Scalability: AI agents can handle increasing volumes of data and tasks without a proportional increase in human resources, thus enabling organizations to scale operations efficiently. Continuous Learning: As these systems are employed, they can learn from interactions and outcomes, further enhancing their capabilities and fostering an adaptive operational environment. Limitations and Considerations Despite the numerous advantages, it is essential to recognize certain limitations and considerations when deploying agentic AI. The effectiveness of these agents is heavily contingent on the quality of the data they utilize and the context in which they operate. In scenarios where enterprise data is fragmented or lacks sufficient context, the performance of AI agents may be compromised. Additionally, human oversight remains a critical factor in ensuring the successful deployment of these systems, as it mitigates the risks associated with automated decision-making. Future Implications of AI Developments Looking forward, the trajectory of AI advancements holds significant implications for the landscape of agentic AI and its role in business workflows. As organizations increasingly integrate these technologies, the evolution of governance models and operational frameworks will likely adapt to accommodate AI agents. The anticipated growth in agent confidence, as reported by technology experts, suggests a future where these systems become an integral part of daily operations, enhancing both efficiency and decision-making capabilities. Moreover, as the technology matures, we can expect breakthroughs in areas requiring advanced reasoning and contextual understanding, further solidifying the role of agentic AI in driving business innovation. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context and Significance of Mixed Reality in Human-AI Collaboration In recent years, the field of Computer Vision and Image Processing has experienced significant advancements, particularly with respect to the integration of Artificial Intelligence (AI) and Mixed Reality (MR) technologies. The emergence of in-situ intelligent mixed reality assistants represents a paradigm shift in how humans collaborate with AI systems in real-time environments. These systems leverage improvements in camera capabilities, lens resolution, and computational power to create immersive experiences that enhance human decision-making processes. Such advancements are not merely technological upgrades; they are catalysts for enhancing productivity and innovation across various sectors, including healthcare, manufacturing, and education. Main Goal of Mixed Reality Assistants The primary objective of the implementation of in-situ intelligent mixed reality assistants is to facilitate adaptive human-AI collaboration. This goal can be achieved by utilizing MR overlays to provide context-sensitive information to users, thereby augmenting their cognitive capabilities. By merging digital content with the physical environment, these systems aim to bridge the gap between human intuition and machine intelligence, allowing for seamless interactions that improve situational awareness and operational efficiency. Advantages of In-Situ Intelligent Mixed Reality Assistants Enhanced Decision-Making: Mixed reality environments enable users to visualize complex data in real-time, facilitating faster and more informed decision-making. Evidence from recent applications demonstrates that professionals who utilize MR tools exhibit improved accuracy and speed in their tasks. Increased Engagement: By creating immersive experiences, MR assistants significantly enhance user engagement. This increased interaction can lead to more effective training and educational outcomes, as users retain information better when they can visualize and manipulate data within a mixed reality context. Collaboration Across Distances: MR technologies facilitate remote collaboration, allowing teams to work together regardless of their physical locations. This capability is particularly beneficial in global organizations where team members may be distributed across various geographies. Real-Time Feedback: The integration of AI with MR allows for real-time data analysis and feedback, empowering users to make immediate corrections and optimizations to their processes. This dynamic interaction reduces the latency typically associated with traditional data processing methods. Caveats and Limitations Despite the numerous advantages, several limitations must be acknowledged. The effectiveness of mixed reality systems is highly contingent on the quality of underlying hardware and software, which can be prohibitively expensive. Additionally, there are challenges related to user adaptation; not all individuals may find the transition to MR environments intuitive. Furthermore, privacy concerns regarding data collection and usage in MR systems must be carefully managed to ensure user trust and compliance with regulations. Future Implications of AI Developments in Mixed Reality Looking ahead, the convergence of AI and mixed reality technologies holds substantial promise for the future of human-AI collaboration. As AI algorithms continue to evolve, the capabilities of mixed reality systems are expected to expand, enabling them to learn from user interactions and adapt more intelligently over time. This evolution could lead to the development of highly personalized MR experiences that cater to individual user needs and preferences, thereby enhancing productivity and creativity in various fields. The growing integration of AI in MR systems will likely also drive innovation in related technologies, further transforming industries and improving outcomes. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
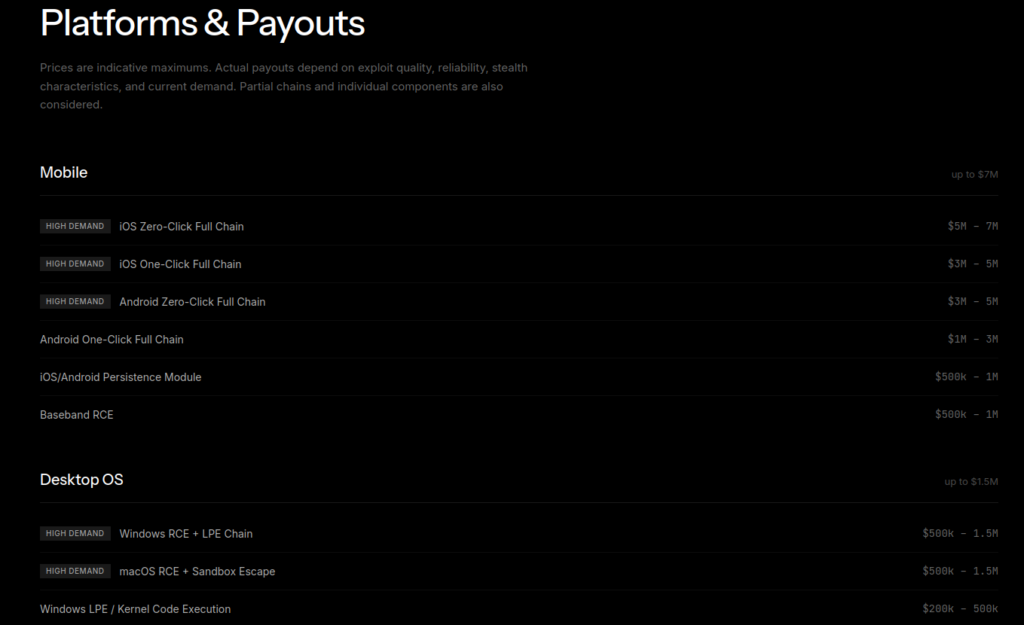
Contextual Overview The landscape of cybersecurity is continuously evolving, marked by the emergence of startups that offer innovative yet controversial solutions. One such entity is IRIS C2, a cybersecurity startup that claims to facilitate the acquisition of zero-day vulnerabilities in widely used software. The company’s operations are managed by individuals with contentious backgrounds, including prior convictions and allegations of fraudulent practices. This context raises questions regarding the credibility and ethical considerations of such startups within the cybersecurity domain, particularly in relation to their impact on data engineering and the broader implications for the industry. Main Goals and Achievements The primary objective of a startup like IRIS C2 is to attract talented vulnerability researchers and exploit developers while capitalizing on the lucrative market for zero-day exploits. By offering significant financial incentives for discovering security vulnerabilities, IRIS C2 aims to establish itself as a leading player in the offensive cybersecurity space. Achieving this goal hinges on the ability to build a reputation that attracts skilled professionals, despite the questionable ethics associated with its founders and their previous ventures. Furthermore, the startup’s success is contingent upon its ability to navigate the regulatory landscape and establish trust among potential clients, particularly within government sectors. Advantages of Engaging with Offensive Cybersecurity Startups Financial Incentives: Startups like IRIS C2 offer substantial rewards for vulnerability findings, with payouts ranging from $10,000 to $7 million. This financial model can motivate talented researchers to contribute their expertise, potentially leading to enhanced cybersecurity measures. Accessibility to Diverse Talent: The recruitment strategy employed by IRIS C2 emphasizes raw talent over formal qualifications, which may help to uncover innovative solutions from a wider pool of individuals, thereby enhancing the overall quality of cybersecurity defenses. Increased Awareness of Vulnerabilities: By actively engaging in the market for zero-day exploits, such startups can bring attention to existing vulnerabilities in popular software, prompting necessary updates and patches from software vendors. Potential for Collaboration: The operational model of engaging with independent researchers fosters a collaborative environment where innovative ideas can flourish, leading to advancements in offensive cybersecurity practices. Limitations and Caveats Despite the potential advantages, there are significant caveats associated with engaging in the offensive cybersecurity market. The ethical implications of working with startups founded by individuals with questionable histories raise concerns about the integrity of the information provided. Moreover, the lack of oversight in the acquisition and dissemination of zero-day vulnerabilities could potentially expose government and private sector clients to greater risks if such vulnerabilities are not responsibly managed. Additionally, the financial model may incentivize researchers to prioritize profit over ethical considerations, leading to a potential undermining of cybersecurity practices. Future Implications and the Role of AI As artificial intelligence (AI) technology advances, its integration into offensive cybersecurity practices is likely to become more prevalent. AI can enhance the ability to identify vulnerabilities and automate exploit development processes, potentially increasing the efficiency of startups like IRIS C2. However, this also raises the stakes regarding the ethical use of such technologies. With AI-driven cyberattacks becoming more sophisticated, the need for robust regulatory frameworks and ethical guidelines will be paramount to ensure that advancements in cybersecurity do not inadvertently contribute to malicious activities. Moreover, the intersection of AI and cybersecurity will necessitate a reevaluation of current practices in the field of data engineering, emphasizing the need for professionals to adapt to emerging technologies while maintaining a commitment to ethical standards. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
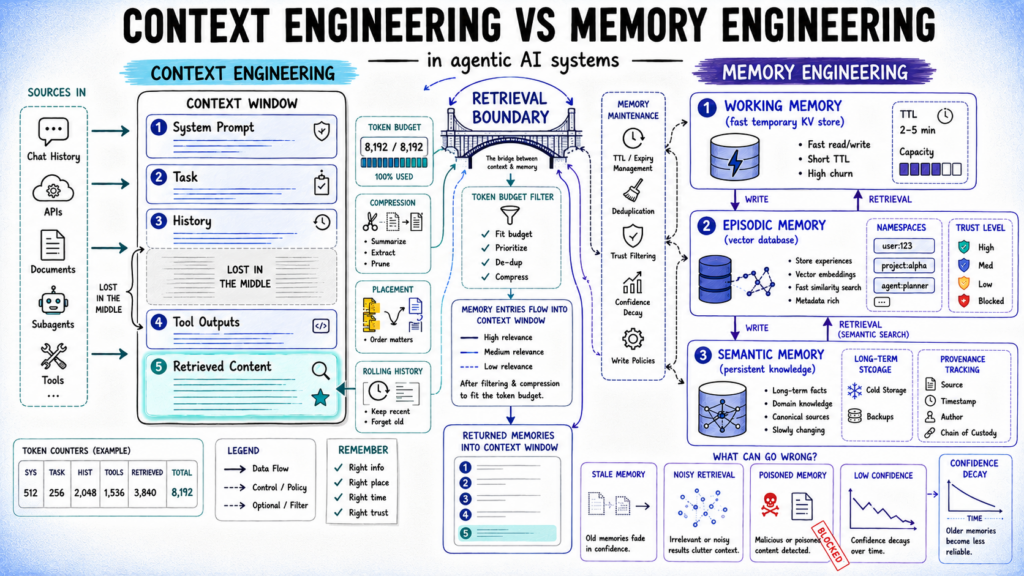
Contextual Framework: Understanding Context and Memory Engineering in Agentic AI Systems In the domain of Applied Machine Learning, particularly in the deployment of agentic AI systems, the interplay between context engineering and memory engineering is vital. These two disciplines address distinct yet interconnected challenges that arise as AI agents navigate complex workflows and multi-session tasks. Context engineering focuses on what information is utilized during a specific inference call, while memory engineering pertains to the mechanisms that ensure relevant information is retained and accessible across multiple interactions. This article delves into the nuances of these engineering disciplines, elucidating their respective roles in enhancing the efficacy of AI systems. Key topics include: The principles of context engineering, encompassing selective inclusion, structural placement, and compression, and their implications for reasoning quality. The fundamentals of memory engineering, covering write policy design, storage layer selection, retrieval strategies, and maintenance, which collectively shape long-term reliability. The intersection of memory and context engineering at the retrieval boundary, highlighting common failure modes when this boundary is not effectively managed. Introduction As AI agents become integral to increasingly intricate workflows, challenges such as information leakage, task constraints, and context confusion emerge. These issues often stem from the lack of clarity in the roles of context engineering and memory engineering, which, although related, fail in unique ways. Understanding the distinctions and interactions between these disciplines is critical for ensuring AI systems perform reliably throughout real-world applications. Main Goal and Achievements The primary goal of aligning context and memory engineering practices is to ensure that AI agents have access to the right information at the right time. Achieving this involves meticulous management of what information enters the context window during inference and what is preserved in memory for future interactions. The objective is to create a seamless integration where memory serves as a foundation for context, allowing the AI to leverage past knowledge effectively while maintaining the relevance and clarity of current tasks. Advantages of Effective Context and Memory Engineering Enhanced Reasoning Quality: Proper context engineering leads to improved inference outcomes by ensuring that only relevant, high-quality information is included in the context window. Increased Long-Term Reliability: Memory engineering facilitates the systematic storage and retrieval of critical information, which enhances the reliability of AI systems over extended periods. Optimized Resource Utilization: By implementing selective inclusion and compression strategies, AI systems can operate more efficiently, thereby reducing computational overhead and resource consumption. Improved User Interaction: Clear memory and context management enhances user experiences through more coherent and contextually aware AI interactions, leading to higher user satisfaction. Scalability: Well-defined engineering practices allow AI systems to scale effectively, managing more extensive datasets and complex workflows without loss of performance. However, these advantages come with caveats. Mismanagement of context and memory can lead to issues such as information overload, retrieval misses, and degraded system performance. Thus, careful design and implementation are essential to mitigate these risks. Future Implications The evolution of AI technologies and methodologies will profoundly affect the landscape of context and memory engineering. As AI systems become increasingly sophisticated, the demand for robust memory architectures and adaptive context engineering will grow. Future advancements may lead to more intelligent, self-optimizing systems capable of dynamically adjusting their memory and context strategies based on real-time feedback and performance metrics. Moreover, the integration of more advanced neural architectures and algorithms will likely enhance the ability of AI agents to understand and manage complex dependencies between context and memory, thereby improving their overall functionality and reliability. As these developments unfold, the potential for AI applications in various sectors, including healthcare, finance, and customer service, will expand significantly, further highlighting the importance of effective context and memory engineering. Conclusion In conclusion, the relationship between context and memory engineering is fundamental to the success of agentic AI systems. By understanding and optimizing these two layers of engineering, practitioners in the field of Applied Machine Learning can build more effective, reliable, and user-friendly AI solutions. The future of AI will undoubtedly necessitate a deeper exploration into these disciplines, ensuring that AI systems not only learn from the past but also act intelligently in the present. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The advent of advanced artificial intelligence (AI) systems has revolutionized various domains, particularly in Natural Language Understanding (NLU) and Language Understanding. A key player in this transformation is the Claude API, which enables developers to integrate sophisticated language models into their applications. This blog post aims to elucidate the steps necessary for utilizing the Claude API within a Python environment, focusing on practical considerations such as response object interpretation, streaming outputs, and effective prompt structuring. These skills are essential for Natural Language Understanding scientists and developers seeking to enhance their applications with AI-driven capabilities. Establishing a Foundation To begin leveraging the Claude API, developers must first meet specific prerequisites, including the installation of Python 3.9 or higher, as well as the creation of a free Claude Console account that provides access to an API key. The significance of utilizing the Claude Python SDK cannot be overstated, as it streamlines API interactions by offering typed response objects, built-in retry mechanisms, and a user-friendly interface. This foundational setup is pivotal for ensuring seamless communication with the Claude API, thereby facilitating the effective integration of language understanding functionalities into applications. Main Goals of Using the Claude API The primary objective of this blog post is to guide users through the process of making their first API call and interpreting the subsequent outputs. Achieving this goal involves a series of methodical steps: Installation of the Claude SDK and proper API key management. Execution of an API call to retrieve meaningful responses from the language model. Understanding the structure of the response object to extract relevant information. Utilizing system prompts to dictate the behavior of the AI in conversations. Implementing streaming responses to enhance user experience during interactions. Advantages of Utilizing the Claude API The Claude API offers several advantages that can significantly benefit developers and NLU scientists: Ease of Integration: The SDK simplifies API interactions, allowing developers to focus on application logic instead of API intricacies. Structured Responses: The API returns structured response objects, making it easier to extract and utilize data effectively. System Prompts: Users can set persistent roles and constraints across conversations, enhancing the contextual relevance of interactions. Streaming Capabilities: Real-time output streaming improves user engagement by providing immediate feedback rather than waiting for complete responses. However, it is essential to recognize limitations, such as the necessity for careful token management to avoid exceeding the model’s context limits and the potential for responses to be cut off if the max_tokens parameter is not adequately set. Future Implications of AI Developments in NLU The implications of ongoing advancements in AI and NLU are profound. As language models like Claude continue to evolve, we can anticipate enhancements in understanding context, sentiment, and even nuances in human communication. These improvements will empower developers to create more sophisticated applications capable of handling complex interactions. Moreover, as the technology matures, we may witness further integration of AI in various sectors, such as education, customer service, and healthcare, transforming how we interact with technology and each other. The future landscape of NLU promises to be dynamic and increasingly intertwined with everyday life, making it essential for professionals in this field to stay informed and adaptable. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
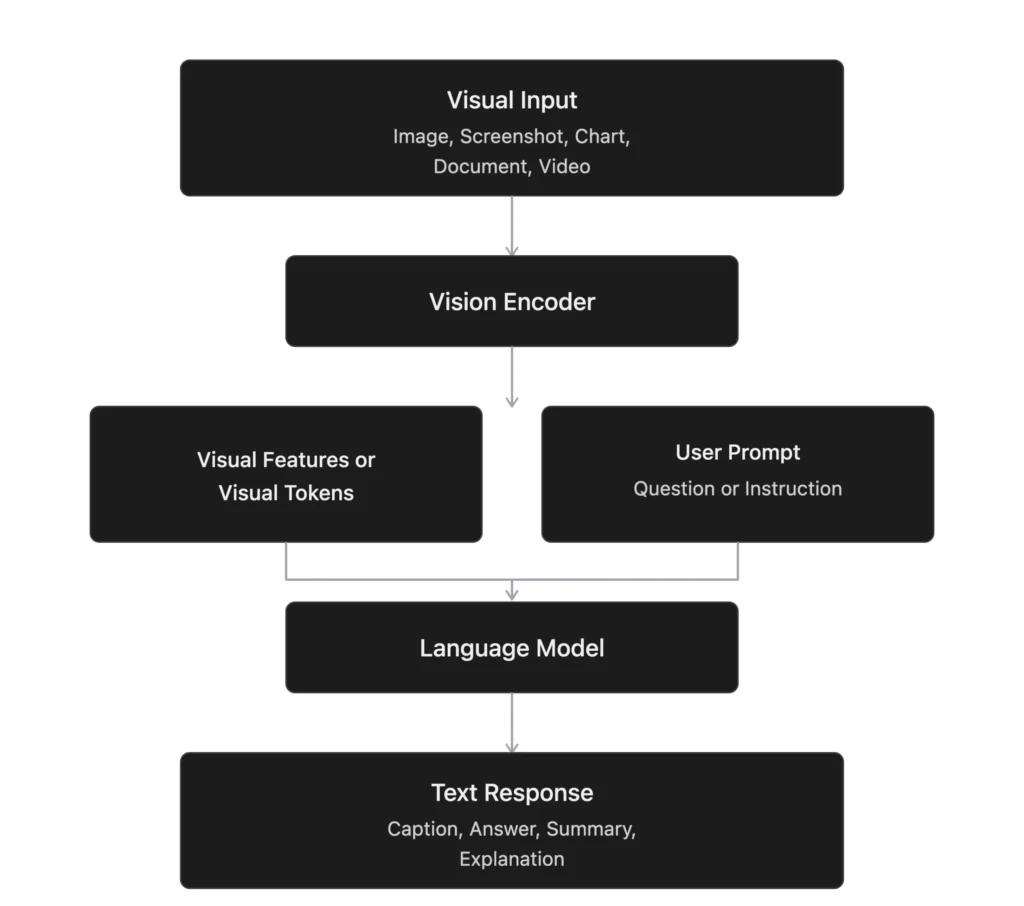
Context Vision Language Models (VLMs) represent a significant advancement in artificial intelligence, uniquely capable of interpreting both visual and textual information. Unlike their predecessors, such as CLIP and BLIP, which primarily bridged images and text, modern VLMs extend their capabilities to encompass complex tasks, including image analysis, document comprehension, chart interpretation, and interactive multimodal engagements. This evolution has made VLMs indispensable across various sectors including education, healthcare, business, automation, and accessibility, enhancing the practical applications of visual AI in real-world scenarios. What Are Modern Vision Language Models? Modern Vision Language Models are sophisticated AI systems engineered to process and understand visual content alongside language. These models are not limited to object recognition; they can articulate contextual narratives, respond to inquiries, read textual data within images, interpret layouts, and perform comparative analyses of visual information. By integrating a vision system that translates images into actionable visual features and a large language model that leverages these features in response to user prompts, VLMs provide a comprehensive approach to understanding multimodal inputs. From CLIP and BLIP to Modern VLMs While CLIP and BLIP laid the groundwork for early VLM development by demonstrating the potential for mapping images and text, modern VLMs have evolved to function as comprehensive multimodal assistants. They possess the capability to execute instructions, engage in dialogue, analyze documents, and reason through visual details. This transition marks a paradigm shift, transforming VLMs from mere image-text models into versatile tools that facilitate user action based on visual context interpretation. Understanding the Functionality of Leading VLMs Key examples of modern VLMs, such as GPT-4o, Gemini, Claude Vision, and Qwen-VL, exemplify the remarkable capabilities of contemporary AI technology. Each model showcases unique strengths: GPT-4o excels in real-time multimodal interaction, seamlessly integrating text, images, audio, and video to create an interactive user experience. Gemini leverages strong reasoning abilities across diverse information types, making it particularly effective for detailed analyses involving long documents, videos, and complex charts. Claude Vision focuses on meticulous visual understanding, providing clear explanations and summaries of complex visual content. Qwen-VL specializes in reading textual information from images and performing advanced document parsing, which is especially useful in Optical Character Recognition (OCR) scenarios. Key Differences Between Modern VLMs The primary distinctions among these models lie in their unique strengths and ideal use cases. For instance, GPT-4o is tailored for interactive user assistance, while Gemini is adept at comprehensive analysis. Conversely, Claude Vision is designed for precise visual communication, and Qwen-VL focuses on structured visual understanding. These differences underscore the importance of selecting the appropriate VLM based on the specific requirements of a task. Strengths and Limitations of Modern VLMs Strengths of Modern VLMs Limitations of Modern VLMs Ability to understand and articulate visual content in natural language. Potential to overlook subtle details or misinterpret unclear images. User-friendly compared to traditional computer vision systems. May present confident but inaccurate answers. Capable of diverse tasks such as summarizing documents and supporting multimodal conversations. Challenges with complex visuals, low-quality images, and contextually rich tasks. Facilitates faster understanding of intricate information. Requires substantial computational resources for effectiveness. Future Implications The ongoing advancements in VLM technology hold significant implications for various sectors. As these models improve in their ability to interpret visual data and provide contextually relevant insights, they will increasingly influence how professionals engage with visual information. For data engineers and analysts, the integration of VLMs into data workflows can enhance efficiency, reduce manual data processing, and facilitate deeper insights into complex datasets. However, as VLMs become more prevalent, the importance of human oversight will remain critical, particularly in sensitive areas such as healthcare and finance, where nuanced understanding is paramount. Conclusion Modern Vision Language Models mark a pivotal development in AI, bridging the gap between visual and linguistic understanding. The transition from earlier models to contemporary VLMs like GPT-4o, Gemini, Claude Vision, and Qwen-VL exemplifies the growing sophistication of AI technologies. While these models offer impressive capabilities across multiple industries, careful consideration of their limitations and the necessity for human oversight will be essential as their applications expand. Frequently Asked Questions Q1. What are modern Vision Language Models? A. Modern Vision Language Models are AI systems that understand and process images and text together, enabling them to describe visuals, read documents, and answer visual questions. Q2. How are modern VLMs different from CLIP and BLIP? A. CLIP and BLIP focused on matching images with text, while modern VLMs can execute complex tasks such as analyzing documents and engaging in conversations. Q3. What are the main limitations of modern VLMs? A. Modern VLMs may miss intricate details, misinterpret unclear visuals, and require significant computational power for optimal performance. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context As the gaming landscape continues to evolve, cloud gaming platforms such as GeForce NOW play a pivotal role in shaping player experiences. In July, GeForce NOW introduces an exciting array of games, including the innovative Monopoly: Star Wars Heroes vs. Villains, alongside twelve additional titles. This serves not only to enhance entertainment but also to stimulate engagement among diverse player demographics. Furthermore, the platform is offering significant savings on membership subscriptions, thereby making high-performance gaming more accessible to a broader audience. Main Goal The primary objective outlined in the original post is to promote GeForce NOW’s extensive gaming offerings while encouraging users to take advantage of limited-time membership discounts. Achieving this goal involves creating awareness about the new game releases and the promotional offers available, which can enhance user engagement and retention. By effectively communicating these incentives, GeForce NOW aims to sustain and grow its user base in a competitive gaming market. Advantages and Evidence Accessibility Across Devices: GeForce NOW allows users to play high-quality games on various devices, including low-powered PCs, Macs, and mobile devices. This flexibility enables gamers to enjoy their favorite titles without the need for high-end hardware, as evidenced by the platform’s emphasis on cross-device functionality. Cost-Effective Gaming Solutions: The current membership discounts offer substantial savings, making premium gaming experiences more affordable. For instance, users can save $35 on a 12-month Performance membership, illustrating GeForce NOW’s commitment to providing value. Diverse Game Library: With the addition of numerous titles each month, including popular franchises, GeForce NOW ensures that players have access to a wide array of gaming experiences. This strategy not only attracts new users but also retains existing ones through continuous engagement. Community Feedback: The community engagement highlighted in the original post, where users express satisfaction with the value offered during sales, underscores the importance of user feedback in shaping service offerings. Positive testimonials can act as a form of social proof, enhancing trust and credibility. Future Implications The advancement of artificial intelligence (AI) technologies is poised to significantly impact the cloud gaming sector. As generative AI models evolve, they could enhance game design, create personalized gaming experiences, and optimize server performance. Moreover, AI-driven data analytics can provide deeper insights into user behavior, allowing companies like GeForce NOW to refine their marketing strategies and tailor content to meet the preferences of their user base. The implications extend beyond mere gaming; as AI continues to integrate into various facets of technology, the potential for innovative features and user experiences in cloud gaming will likely expand, further enriching the gaming ecosystem. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context: The Intersection of AI and Operational Excellence The integration of artificial intelligence (AI) into organizational frameworks represents a transformative opportunity for enhancing operational efficiency. However, as highlighted in recent discussions on achieving operational excellence through AI, the potential benefits of such technologies can only be realized when they are anchored within robust operational structures. Organizations that prioritize process discipline are better equipped to leverage AI capabilities effectively, as they already employ data-driven decision-making protocols. This cultural readiness is essential for harnessing the full value of AI systems, creating a synergistic relationship between technology and established processes. The Goal of Achieving Operational Excellence with AI The principal objective of incorporating AI into operational frameworks is to enhance process efficiencies that ultimately lead to superior business outcomes. This goal can be achieved through a systematic approach that emphasizes the integration of AI technologies with existing operational protocols. Companies that have laid a solid foundation in process discipline can better channel AI tools, thereby fostering an environment where both technological advancements and operational strategies work in tandem. Advantages of Integrating AI with Established Operational Processes 1. **Enhanced Decision-Making**: Organizations that possess mature process disciplines are already familiar with data-driven methodologies. The integration of AI into these frameworks can refine decision-making processes, enabling faster and more accurate responses to market changes. 2. **Increased Efficiency**: AI can streamline operations by automating repetitive tasks and providing insights that help optimize workflows. This leads to significant time and cost savings, which can be reinvested into other areas of the business. 3. **Scalability**: Well-defined processes allow organizations to scale AI solutions effectively. When AI tools are embedded within existing operational systems, they can be expanded or adapted with greater ease, facilitating growth without compromising quality. 4. **Improved Collaboration**: The fusion of AI and established processes fosters a collaborative workplace culture. Teams can utilize AI-generated insights to work more cohesively, aligning their objectives and strategies seamlessly. 5. **Sustainable Innovation**: Organizations that successfully integrate AI with their operational frameworks cultivate an environment of continuous improvement. This positions them to adapt swiftly to technological advancements and market demands, ensuring long-term sustainability. Despite these advantages, there are caveats to consider. Organizations must ensure that their foundational processes are sufficiently robust to support the complexities introduced by AI. Failure to do so may result in operational disruptions or diminished returns on AI investments. Future Implications of AI Developments in Operational Excellence As AI technologies continue to evolve, their implications for operational excellence will expand significantly. Future advancements in AI capabilities—such as machine learning, natural language processing, and predictive analytics—will further enhance the ability of organizations to optimize their processes. The increasing sophistication of AI tools will likely lead to even more profound integrations with operational strategies, driving innovation and efficiency to unprecedented levels. However, as organizations embrace these advancements, they must remain vigilant in maintaining the integrity of their foundational processes. The success of AI integration hinges not only on the technologies themselves but also on the organizational culture that supports them. Companies that prioritize this holistic approach will be best positioned to navigate the complexities of the future business landscape. In conclusion, the interplay between AI and operational excellence is pivotal for organizations seeking to thrive in an increasingly competitive environment. By establishing a strong foundation built on process discipline, companies can unlock the transformative potential of AI, paving the way for sustainable growth and innovation. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The landscape of terminal-based AI agents has undergone substantial transformation recently, particularly affecting developers in the fields of Computer Vision and Image Processing. These changes necessitate a deeper understanding of the tools available for managing and optimizing workflows, especially as the technologies powering these agents evolve. Notably, the transition from Google’s Gemini CLI to Antigravity CLI represents a pivotal shift that merits careful consideration for practitioners relying on these technologies. Context and Significance The retirement of Gemini CLI, a tool that has served as an essential resource for many developers, underscores the importance of adaptability within the technological ecosystem. The introduction of Antigravity CLI, while offering advanced features, raises concerns regarding its closed-source nature, which contrasts sharply with the open-source ethos that characterized its predecessor. Such transitions can significantly affect existing scripts and CI/CD pipelines, making it imperative for developers to reassess their tools and workflows. Main Goals and Achievements The primary goal of understanding these shifts in AI CLI tools is to ensure that developers can maintain efficient and effective workflows while leveraging the latest advancements in technology. This can be achieved by: Assessing the implications of transitioning to Antigravity CLI and its effects on existing systems. Exploring new features in Claude Code, particularly its enhanced context window and Dynamic Workflows, to improve task automation. Examining the architecture of OpenClaw, including its extensibility and security considerations, to maximize its potential in real-world applications. Advantages and Limitations Several key advantages arise from the recent developments in AI CLI tools: Enhanced Functionality: Claude Code’s Opus 4.8 and Fable 5 models offer a 1M-token context window, greatly facilitating the handling of larger datasets typical in Computer Vision tasks. Open Source Opportunities: OpenClaw’s growth within the GitHub community illustrates the collaborative potential of open-source software, allowing Vision Scientists to contribute to and benefit from shared developments. Dynamic Workflows: The introduction of Dynamic Workflows in Claude Code streamlines processes, thus optimizing productivity for developers engaged in complex image processing tasks. However, it is essential to note certain limitations: Transition Challenges: The move from Gemini CLI to Antigravity CLI may disrupt existing workflows, requiring developers to invest time in adapting or rewriting scripts. Security Concerns: Antigravity CLI’s closed-source nature introduces potential vulnerabilities that must be carefully managed, particularly given the sensitive data often processed in the field of Computer Vision. Future Implications The advancements in AI CLI tools signal a broader trend toward the integration of AI in various domains, particularly in Computer Vision and Image Processing. As these tools become more sophisticated, they will likely facilitate increased automation and efficiency in data handling and analysis. This evolution is poised to empower Vision Scientists to deploy more complex models and algorithms, ultimately leading to breakthroughs in image recognition, object detection, and beyond. Moreover, the ongoing development of both proprietary and open-source tools will continue to shape the landscape, fostering a competitive environment that incentivizes innovation. As AI technologies advance, it is crucial for professionals in the field to remain agile and informed, ensuring that they leverage these tools to their fullest potential. Conclusion In summary, the evolving AI CLI landscape presents both challenges and opportunities for developers in the Computer Vision and Image Processing sectors. Understanding the implications of these changes is vital for optimizing workflows and harnessing the full power of emerging technologies. By staying informed and adaptable, Vision Scientists can navigate these transitions effectively, paving the way for future advancements in their field. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context In the realm of software development, managing sensitive information, often referred to as “secrets,” is crucial for maintaining security and integrity. GitHub’s initiative to enhance secrets hygiene serves as a compelling case study, illustrating the challenges faced by organizations in safeguarding their data. Over a period of nine months, GitHub successfully identified and mitigated over 20,000 alerts related to potential secrets across its vast repository landscape, culminating in a state of zero open alerts. This endeavor not only reflects a commitment to security but also offers valuable insights for organizations, especially in the Big Data Engineering sector, where the abundance of data necessitates stringent measures for data protection. Main Goal and Achievements The primary goal of GitHub’s secret scanning initiative was to enhance the security posture by effectively identifying and remediating secrets within their codebase. This objective was achieved through a systematic approach that encompassed several phases: stopping the accumulation of new secrets, understanding and triaging existing alerts, validating the status of credentials, and driving accountability through ownership. By implementing these strategies, GitHub not only reached operational efficiency but also fostered a culture of security awareness among its teams. Advantages of Effective Secrets Management Reduction of Security Risks: By identifying and remediating potential secrets, organizations can significantly mitigate the risk of unauthorized access to sensitive information. GitHub’s approach demonstrated that a significant majority of alerts could be categorized as low-risk, allowing for focused remediation efforts. Improved Operational Efficiency: The phased approach adopted by GitHub facilitated a systematic resolution of alerts, enhancing operational workflows. By automating certain processes and employing bulk closure strategies, GitHub was able to manage a high volume of alerts without overwhelming their security teams. Enhanced Collaboration: The initiative required cross-functional collaboration among various teams, including customer support and security incident response. This not only improved the effectiveness of the remediation process but also fostered a culture of collective responsibility for security across the organization. Data-Driven Decision Making: The ability to validate the status of credentials allowed GitHub to prioritize remediation efforts effectively. By differentiating between live and inactive credentials, the organization could focus on high-risk areas, thereby optimizing resource allocation. Caveats and Limitations While the advantages of effective secrets management are evident, certain limitations must be acknowledged. The initial count of alerts can be misleading, as demonstrated by GitHub’s experience where the majority of alerts were inactive. Additionally, the implementation of such a comprehensive approach requires significant organizational commitment and resources. Organizations must also consider the potential for operational disruptions when rewriting git history or altering existing repositories. Future Implications Looking ahead, the integration of artificial intelligence (AI) into secrets management processes is poised to revolutionize the field. AI can enhance the accuracy of alerts by employing machine learning algorithms to identify patterns and anomalies in code. Furthermore, AI-driven tools can automate the remediation process, reducing the need for manual intervention and minimizing human error. As organizations continue to grapple with the complexities of data security in an increasingly digital landscape, leveraging AI technologies will be essential for maintaining robust security practices. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here