
Introduction The advent of the Model Context Protocol (MCP) has transformed the landscape of AI agent development, particularly in the context of applied machine learning. Previously, integrating AI agents with external tools necessitated extensive custom coding for each individual connection. However, following the open-sourcing of MCP by Anthropic in late 2024, major tech companies such as OpenAI, Google, and Microsoft adopted this standard throughout 2025, culminating in its donation to a Linux Foundation body. This evolution has positioned MCP as a universal standard, akin to USB-C for agent tooling, allowing seamless interoperability among compliant tools and agents. Nonetheless, the rapid proliferation of MCP-compatible servers has led to a significant amount of noise in the ecosystem, making it imperative for practitioners to identify effective and reliable solutions. Main Goal and Achievement The primary goal of the original article is to highlight five essential MCP servers that enhance the capabilities of AI agents in high-performance development environments. By selecting servers that provide tangible improvements in agent functionality rather than merely relying on popularity metrics, practitioners can optimize their development setups. To achieve this, developers must integrate these servers thoughtfully into their workflows, ensuring that the chosen tools are actively maintained and relevant to their specific use cases. Advantages of Using MCP Servers Enhanced Development Workflow: The GitHub MCP Server serves as the foundational element for agents needing to interact with development workflows, allowing them to perform tasks such as opening pull requests and triaging issues efficiently. Improved Browser Interactions: Microsoft’s Playwright MCP server significantly improves browser automation by providing structured data access through the accessibility tree, thus facilitating faster and more reliable web interactions. Reduction of Coding Errors: Context7 injects up-to-date library documentation directly into the agent’s context, which mitigates the risk of coding errors typically introduced by outdated or nonexistent API references. Precision in Code Editing: Serena utilizes the Language Server Protocol (LSP) to provide semantic understanding, allowing agents to edit code with precision rather than relying on basic text pattern matching. Dependable Infrastructure: The collection of official reference servers provides essential functionalities that support structured reasoning for agents, ensuring robust local access and memory management. Despite these advantages, it is crucial to recognize certain limitations. Some servers may be maintained primarily as educational references rather than production-ready solutions. Additionally, several popular servers have been archived, necessitating due diligence to ensure that the selected tools are actively supported and functional. Future Implications The advancements in AI and the continuous evolution of protocols like MCP are expected to significantly reshape the future of agent-based development. As AI systems become more sophisticated, the demand for interoperability among diverse tools will grow, necessitating further refinements in agent capabilities. Additionally, as the ecosystem matures, we may anticipate an increase in standardized solutions that promote efficiency and reliability, empowering machine learning practitioners to leverage these advancements for enhanced productivity and innovation. The implications of these developments will likely extend beyond technical enhancements, influencing the broader landscape of software development and AI integration. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The integration of advanced programming interfaces, such as Claude Code, has transformed the landscape of Natural Language Understanding (NLU). However, a significant number of users fail to capitalize on the full potential of these tools, often becoming stagnant after initial installation. This stagnation can lead to chronic inefficiencies, such as the inability to maintain contextual awareness and repeated prompts that hinder productivity. Understanding that these issues stem primarily from suboptimal setup configurations and not inherent limitations of the model itself is crucial for achieving high performance in agentic programming. Understanding High Performance in Claude Code The primary objective of optimizing Claude Code for high-performance agentic programming is to bridge the gap between sensible defaults and peak operational effectiveness. Achieving this requires a comprehensive understanding of critical configuration files, permissions, and command habits, which are often overlooked by novice users. This guide elucidates how to effectively configure these aspects to ensure sustained productivity and contextual integrity during complex programming tasks. Key Advantages of Optimizing Claude Code Enhanced Context Management: By properly configuring the .claude/ and CLAUDE.md files, users can streamline context management, thereby reducing the frequency of context degradation. This allows for more coherent and productive interactions over extended sessions. Reduced Permission Interruptions: The settings.json file enables users to set precise permission rules. This minimizes the disruptions caused by repetitive permission prompts, allowing users to focus on their tasks rather than administrative hurdles. Improved Customization: The ability to create custom commands and hooks not only augments the functionality of Claude Code but also allows for tailored interactions that better fit specific project needs, enhancing overall workflow efficiency. Scalability via Subagents: The incorporation of subagents facilitates parallel processing of tasks, which is invaluable for handling large codebases or complex projects. This feature allows for delegating specific tasks to subagents, freeing up the main session for other critical processes. Documentation and Memory Maintenance: By utilizing the CLAUDE.md file effectively, users can maintain a living document that captures essential project details, ensuring that key configurations and instructions are readily available and up to date. Caveats and Limitations While optimizing Claude Code presents numerous advantages, it is essential to acknowledge certain limitations. For instance, the initial setup may require a steep learning curve for users unfamiliar with command-line interfaces or configuration files. Additionally, the performance gains are contingent on the user’s commitment to maintaining the configuration and regularly updating it as project requirements evolve. Failure to do so may result in a reversion to less efficient default behaviors. Future Implications for AI and NLU The ongoing advancements in artificial intelligence will likely further influence the NLU landscape, enhancing the capabilities of tools like Claude Code. As AI continues to evolve, we can anticipate more sophisticated models that integrate seamlessly with user workflows, offering real-time contextual awareness and adaptive permissions. These developments could lead to even greater efficiencies in programming, enabling NLU scientists to focus more on innovation rather than overcoming operational limitations. The future of agentic programming appears promising, with the potential for more intuitive and powerful tools that continue to push the boundaries of what is achievable in natural language understanding. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
Context In the realm of machine learning, tabular foundation models have emerged as a novel category capable of performing zero-shot predictions on tabular datasets. These models are pretrained on a broad distribution of synthetic tables, enabling them to adapt to new datasets without the need for gradient updates. Among these models, TabICL stands out as a powerful open-source solution. This discussion elucidates the workings of TabICL and positions its performance against established models like XGBoost, particularly in the context of credit-risk datasets, all while employing R in conjunction with Python through the reticulate package. Understanding Tabular Foundation Models A tabular foundation model is characterized by three fundamental components: Pretraining on diverse datasets: Unlike traditional models that learn from a single dataset, tabular foundation models leverage a distribution of tables for pretraining. In-context transferability: These models can transfer knowledge to new datasets, utilizing existing training data to make predictions on test data within a single forward pass. Transformer architecture: Operating on rows of tables rather than tokens, these models utilize a sequence transformer architecture similar to that of large language models (LLMs). The first point highlights a significant divergence from text and vision models, as there is no existing corpus of labeled tables. Instead, models like TabICL harness synthetic data, engaging in a pretraining task that involves predicting targets from held-out rows based on given rows of synthetic tables. Mechanism of TabICL TabICL operates in two distinct stages: Column-then-row attention: Initially, each column is independently processed to create fixed-dimensional embeddings, followed by a row-wise attention mechanism that generates a unified row embedding, independent of the schema. Transformer ICL over rows: The model utilizes row embeddings for both training and testing, allowing self-attention mechanisms to function without gradient updates during inference. This architecture facilitates zero-shot transfer by aligning pretraining objectives with inference tasks, thus enabling efficient scaling to larger datasets compared to other models. Setting Up the Environment with Reticulate TabICL is primarily designed for Python, and its integration with R necessitates the reticulate package. The setup process involves installing necessary Python libraries, including TabICL, Torch, Pandas, and Scikit-learn, to establish a compatible environment for executing predictions. Applying TabICL: Predicting Credit Defaults Utilizing a credit dataset akin to LendingClub, the objective is to predict defaults (represented by a binary target). The dataset enables a comprehensive analysis of TabICL’s predictive capabilities without extensive preprocessing, provided categorical variables are appropriately formatted. The model’s efficiency is reflected in its rapid fitting process, which merely stores training data rather than performing extensive computations during this phase. Comparative Evaluation of TabICL and XGBoost In evaluating TabICL against XGBoost, a standard tuning process for XGBoost involves a grid search and cross-validation, which can be time-consuming. In contrast, TabICL’s approach allows for immediate predictions post-fitting without necessitating extensive tuning, demonstrating its utility for quickly establishing performance baselines. Experiments reveal that TabICL can achieve competitive performance metrics, such as ROC AUC scores, comparable to those of tuned XGBoost models, underscoring its potential as a robust alternative in specific scenarios. Observations from the Application Competing Performance: TabICL’s zero-shot ROC AUC performance is noteworthy, rivaling that of a well-tuned XGBoost model. No Tuning Loop Advantage: The absence of a tuning loop in TabICL simplifies the modeling process, making it suitable for rapid assessments and cold starts. Resource Considerations: While TabICL offers significant advantages, its initial setup requires downloading a pretrained checkpoint, and its resource demands increase with the complexity of the dataset. Appropriate Use Cases for TabICL TabICL is particularly advantageous in cases where: A rapid baseline is required without extensive tuning. The dataset size is manageable, ideally in the range of hundreds to tens of thousands of rows, where in-context learning is most effective. A zero-shot approach is desired for quick analyses across multiple datasets. The task at hand involves classification, though newer versions of TabICL extend support to regression and time-series forecasting. Conversely, TabICL may not be the best choice when: Interpretability or monotonicity is crucial, particularly in regulated environments. Handling very large datasets is necessary, where traditional models may maintain accuracy more effectively. Domain-specific preprocessing for missing values is required. Future Implications The advancement of artificial intelligence and machine learning technologies heralds a transformative period for data analytics and insights. As foundation models like TabICL continue to evolve, their integration into mainstream data engineering practices is likely to augment the efficiency and efficacy of predictive analytics. Future developments may include enhancements in interpretability, scalability for larger datasets, and improved handling of domain-specific requirements, ultimately leading to more robust decision-making frameworks in data-driven industries. Conclusion Tabular foundation models, exemplified by TabICL, represent a significant evolution in machine learning methodologies, offering zero-shot capabilities that simplify the modeling process. While they do not entirely replace established models like XGBoost, they provide a valuable alternative for specific use cases, particularly in smaller datasets and rapid scenario assessments. As the field progresses, the interplay between traditional machine learning techniques and emerging foundation models will continue to shape the landscape of data analytics and insights. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview of Kimi K3 and Its Significance in Generative AI On July 27, 2026, Moonshot AI, a Beijing-based artificial intelligence startup backed by Alibaba, will officially release the Kimi K3, which is touted as the largest open-source AI model globally, featuring an unprecedented 2.8 trillion parameters. This release emerges as a crucial development in the ongoing global AI arms race, particularly as it approaches the 2026 World Artificial Intelligence Conference in Shanghai. The unveiling of K3 not only signifies a resurgence for Moonshot AI, which faced a decline in market position due to competition from DeepSeek, but also represents a pivotal moment for the open-source AI movement. Main Goals and Achievements The primary goal of releasing Kimi K3 is to establish Moonshot AI as a leading entity in the open-source AI community while demonstrating that open-source models can rival the performance of top proprietary systems, such as those developed by Anthropic and OpenAI. This objective can be achieved through several strategies, including: Leveraging extensive architectural innovations, such as the hybrid linear attention mechanism and Attention Residuals, which enhance model performance. Offering competitive pricing structures for API access, thus encouraging broader adoption. Engaging the developer community through open-access model weights, thereby fostering collaboration and innovation. Advantages of Kimi K3 for Generative AI Scientists The release of Kimi K3 offers several advantages that can significantly benefit Generative AI scientists: Enhanced Model Performance: Kimi K3 is benchmarked to perform closely with leading proprietary models, achieving scores of 1,687 on GDPval-AA v2 and 91.2 on BrowseComp. These metrics indicate that K3 can effectively handle real-world tasks across diverse industries. Autonomous Capabilities: The model’s ability to autonomously design a chip and execute complex tasks over extended periods, as demonstrated in its 48-hour chip design project, showcases its potential for practical applications beyond mere text generation. Open-Source Accessibility: By offering a large-scale open-source model, Kimi K3 allows researchers to fine-tune and self-host the model without dependency on proprietary systems, thus enabling greater flexibility in experimentation. Cost-Effective Solutions: Kimi K3’s pricing structure at $3 per million input tokens and $15 per million output tokens offers a competitive alternative to similar models, potentially lowering the cost of AI deployment for organizations. However, it is essential to consider the limitations associated with operating such a large model, including the substantial computational resources required for training and inference, which may not be feasible for all organizations. Future Implications of AI Developments The emergence of Kimi K3 heralds significant implications for the future landscape of Generative AI. As open-source models like K3 approach the performance levels of proprietary systems, the dynamics of enterprise AI strategy will shift: Reevaluation of Proprietary Models: The growing parity in performance between open-source and proprietary models may compel organizations to reconsider their reliance on expensive proprietary solutions, as K3 challenges the justification for premium pricing based solely on capability. Focus on Autonomous Technical Workforces: Kimi K3’s demonstrated capabilities to autonomously manage complex projects indicate that future AI models may evolve from serving as productivity tools to functioning as autonomous agents capable of executing multi-day, intricate tasks. Geopolitical Considerations: The release of K3 as a formidable open-source model positions China as a significant player in the global AI arena, potentially reshaping the geopolitical landscape and fostering increased competition and collaboration among global AI developers. In light of these developments, Kimi K3 not only represents a technological milestone for Moonshot AI but also signals a transformative shift in how Generative AI can be applied across various sectors, positioning it as a critical component of future enterprise strategies. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context: Understanding AI Audits Through Stratagems The field of Artificial Intelligence (AI) is complex and rapidly evolving, with applications spanning numerous sectors, including finance, healthcare, and autonomous systems. A critical aspect of ensuring the reliability and integrity of AI systems is conducting thorough audits of their underlying models and evaluation pipelines. The original post, “Stratagems #16: Mark Left a Hole in His AI Audit. Lena Counted Every Layer,” illustrates the nuanced dynamics of information management and strategic oversight during an AI audit scenario. By employing the ancient wisdom of the 36 Stratagems, particularly the principle of allowing opponents to feel secure before launching a calculated strike, the narrative encapsulates the importance of careful evaluation and systematic investigation in AI audits. Main Goal: Effective AI Model Evaluation The primary goal articulated in the original post revolves around the necessity for comprehensive evaluation of AI model performance, particularly regarding data integrity and exclusion criteria within evaluation datasets. This can be achieved through rigorous auditing processes that involve: In-depth analysis of training distributions and evaluation metrics. Identification of systematic biases or exclusions that may compromise the model’s accuracy. Implementation of recommended fixes that enhance the model’s predictive capabilities. Advantages of Thorough AI Audits Conducting meticulous AI audits offers several advantages that directly enhance the reliability of AI systems: Improved Data Integrity: The narrative underscores the significance of validating data distributions to ensure that low-score samples are not systematically excluded. This leads to a more robust evaluation of model performance. Enhanced Transparency: By documenting findings and recommendations in audit reports, stakeholders gain clearer insights into potential vulnerabilities within AI systems. This transparency is critical for fostering trust among users and clients. Proactive Issue Identification: The ability to identify recurrent patterns of exclusion across different projects allows for the anticipation of future challenges, facilitating timely interventions that can mitigate risks before they escalate. Strategic Decision-Making: Through careful layering of information, as demonstrated in the post, stakeholders can make informed decisions without exposing every detail at once, maintaining strategic advantage while ensuring necessary actions are taken. Limitations and Caveats While the benefits of thorough AI audits are significant, several limitations must be acknowledged: Dependence on Accurate Data: The effectiveness of an audit is contingent upon the quality and completeness of the data provided. Incomplete or inaccurate datasets can lead to flawed conclusions. Resource Intensive: Comprehensive auditing processes require significant time and expertise, which may not be feasible for all organizations, particularly smaller firms with limited resources. Resistance to Change: Stakeholders may resist implementing recommended changes, particularly if they have previously invested heavily in existing systems. This can hinder the adoption of necessary improvements. Future Implications for AI Developments As AI technologies continue to advance, the implications for auditing practices will be profound: Increased Complexity: Future AI systems will likely incorporate more intricate algorithms and larger datasets, necessitating even more sophisticated auditing techniques to ensure reliability. Integration of Automated Audits: The potential for automated auditing tools powered by AI could transform how audits are conducted, enabling real-time monitoring and issue detection. Regulatory Pressure: As AI becomes more pervasive, regulatory bodies may impose stricter requirements for auditing and transparency, driving organizations to adopt comprehensive audit practices proactively. In conclusion, the storyline encapsulated in the original post not only highlights the intricacies of AI audits but also emphasizes the critical need for vigilance in ensuring data integrity and model reliability. As the field of AI continues to evolve, these principles will remain essential for guiding future practices and fostering trust in AI technologies. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
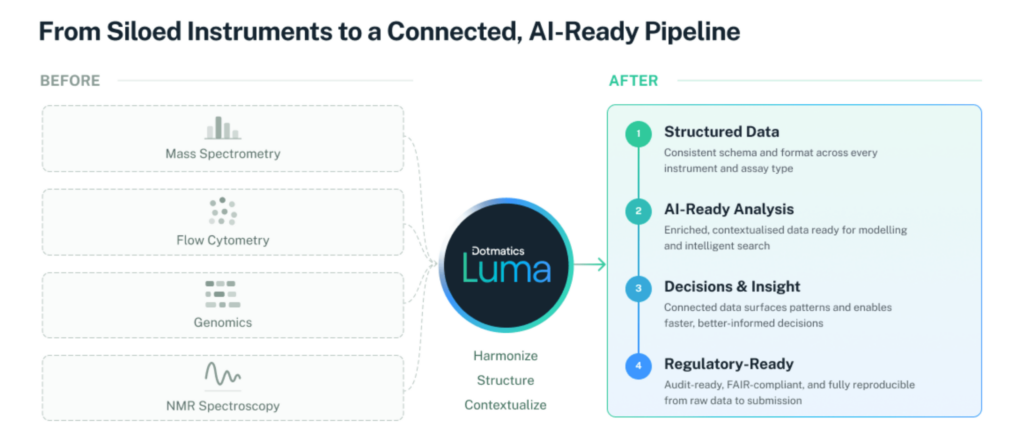
Context: Bridging the Divide Between Scientific Data and Insight The contemporary landscape of scientific research is characterized by the generation of vast quantities of data, often exceeding the capacity of traditional data management techniques. In a typical research organization, numerous instruments in wet labs and associated partner networks produce extensive datasets, frequently residing in isolated silos. This separation not only complicates data accessibility but also hinders the decision-making processes that rely on these datasets. The primary challenge lies not in the sheer volume of data but in maintaining the contextual integrity of this information as it traverses various analytical stages. The loss of context can lead to inefficient workflows, prompting researchers to waste valuable time on data reconstruction or reruns rather than advancing their investigations. Moreover, when artificial intelligence (AI) models are trained on fragmented datasets, the reliability of their outputs becomes questionable. Main Goal: Achieving AI-Ready Science Through Integrated Platforms The principal aim of integrating platforms like Dotmatics Luma and Databricks is to create a cohesive environment where scientific data can be harmonized and rendered AI-ready. This integration is achieved by employing a dual-faceted approach: implementing a dedicated platform tailored for scientific data and providing an enterprise-grade infrastructure that can support large-scale operations. The collaboration between Luma and Databricks exemplifies an effective strategy to close the gap between data generation and actionable insights. Advantages of the Luma and Databricks Integration Continuous Data Capture: Luma facilitates the automatic and uninterrupted capture of scientific data from instruments, ensuring that data is structured and available in real time. This minimizes disruptions to existing workflows and enhances research efficiency. Contextual Data Harmonization: By converting unstructured raw outputs into FAIR-compliant data, Luma ensures that datasets are findable, accessible, interoperable, and reusable. This harmonization fosters a robust foundation for subsequent analyses and AI applications. Scalable Infrastructure: Databricks provides the necessary infrastructure for managing vast amounts of scientific data across the enterprise, allowing for seamless integration with various business intelligence systems, thereby enhancing organizational decision-making. Enhanced Collaboration: The Delta Sharing feature enables secure and governed data sharing with third-party collaborators, including contract research organizations and academic institutions, without compromising data integrity. Faster Path to AI-Ready Science: The combination of Luma and Databricks offers a streamlined route to AI-ready science, ensuring that the rigor of scientific inquiry is upheld throughout the research lifecycle, from discovery to regulatory submission. Future Implications: The Impact of AI on Big Data Engineering The integration of AI in scientific workflows heralds significant transformations within the realm of Big Data Engineering. As organizations increasingly adopt AI-driven solutions, the demand for harmonized and contextualized datasets will escalate. This will necessitate the continuous evolution of data engineering practices to accommodate the complexities of AI applications. Moreover, the ability to utilize AI for real-time data analysis and decision-making will fundamentally alter the dynamics of research, enabling quicker hypothesis testing and accelerating the pace of scientific discovery. Consequently, the role of Data Engineers will likely expand to encompass not only data management but also the integration of AI capabilities into scientific workflows, thereby elevating their significance in the research ecosystem. Conclusion The collaboration between Dotmatics Luma and Databricks exemplifies a transformative approach to overcoming the challenges faced in modern scientific research. By creating a unified platform that harmonizes scientific data and provides robust infrastructure, organizations can achieve AI-ready insights while maintaining the integrity of their research processes. As AI technology continues to evolve, its integration into the scientific workflow will redefine the roles and responsibilities of Data Engineers, further emphasizing the importance of scalable and contextualized data management strategies. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
Contextual Understanding of Decay in Machine Learning Models The context window serves as a foundational feature in advanced machine learning models, especially in the realm of natural language processing (NLP). This window, typically measured in tokens, encapsulates the system prompt alongside an evolving history of interactions, which includes prompts, responses, and tool calls. It is imperative to acknowledge that the model does not retain any internal state between interactions; rather, it depends on the context window as the sole mechanism for recalling prior exchanges. This inherent limitation can lead to a phenomenon known as context rot, where the quality of the model’s output diminishes over time due to the contents of the context window. Context rot can be categorized into two primary types: intrinsic rot and content rot. Intrinsic rot arises from the model’s architectural constraints, specifically its attention mechanism which influences how it prioritizes information. Conversely, content rot refers to the accumulation of stale, erroneous, or contradictory information within a session. The management of content rot is particularly vital, as it is within the control of the user and can significantly enhance the performance of tools like Claude Code. Main Goal and Its Achievement The primary objective articulated in the original post is to provide insights into the degradation of model performance due to context rot and to offer strategies for effective management of this phenomenon. Achieving this involves actively governing the contents of the context window to mitigate both intrinsic and content rot. By understanding the limitations imposed by intrinsic rot, users can better strategize how to structure their interactions with the model. Furthermore, by managing content rot—through careful curation and auditing of the context—users can significantly enhance the utility and accuracy of the model’s outputs. Advantages of Managing Context in Machine Learning Models Improved Output Quality: By actively managing the context, users can ensure that only relevant and accurate information is included, thus enhancing the model’s ability to generate high-quality outputs. Reduced Confusion During Interactions: Effective governance of the context window minimizes the chances of introducing unnecessary noise, leading to clearer and more focused interactions with the model. Enhanced Efficiency: By pruning irrelevant information and streamlining the context, users can facilitate quicker response times and more efficient workflows. Greater Control Over Model Behavior: Users can guide the model’s focus by curating the context, allowing for a more directed and purposeful use of the model’s capabilities. Facilitation of Learning and Adaptation: Consistent management of the context aids in reinforcing desired behaviors in the model, fostering a more adaptive learning environment. However, it is essential to note some caveats. The effectiveness of context management may vary depending on the specific architecture of the model in use and the complexity of the tasks being performed. Users may need to invest time in refining their context management strategies to maximize the advantages offered. Future Implications of AI Developments The ongoing advancements in artificial intelligence and machine learning are likely to have profound implications for the management of context within models. As models become increasingly sophisticated, the mechanisms for attention and context handling may evolve, potentially reducing the incidence of context rot. Future iterations of machine learning models may incorporate more dynamic and adaptable context management systems that learn from user interactions and automatically prune irrelevant information. Moreover, the integration of more robust feedback loops could enhance the models’ ability to self-correct and improve their outputs over time. The implications extend beyond mere performance enhancements; they may fundamentally alter how practitioners interact with AI tools, fostering a more intuitive and effective collaborative environment. As AI continues to mature, the importance of context management will remain a critical aspect of maximizing the efficacy and reliability of machine learning applications. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
Introduction In the realm of Natural Language Processing (NLP), the ability to generate structured outputs from Large Language Models (LLMs) has been a significant challenge. Traditionally, obtaining precise formats, such as JSON objects, required a combination of well-crafted prompts and an element of chance. The recent emergence of an innovative open-source library, known as Outlines, promises to transform this landscape. This library is engineered to mitigate common pitfalls associated with LLM outputs—including the infamous phenomenon of hallucinations—by introducing deterministic certainty into the generation process. This article delves into the capabilities of Outlines, with a focus on practical applications using Python. Understanding Outlines: Ensuring Structured Outputs The primary goal of the Outlines library is to enable the generation of structured outputs with a high degree of reliability. At the inference level, Outlines functions by masking syntactically invalid tokens during the output generation phase, rather than attempting to rectify erroneous text post-generation. This mechanism effectively enforces compliance with the desired output format, thus ensuring that the generated content adheres to predefined structures. Main Goal and Achievements The overarching objective of utilizing Outlines is to achieve consistent and structured outputs from LLMs. This is accomplished through the introduction of constraints at the inference stage, compelling the model to generate outputs that strictly follow established formats. By leveraging features such as the generate.choice() function, users can ensure that only valid options are selected from an approved list, thus enhancing the accuracy of generated responses. Advantages of Using Outlines Enhanced Output Reliability: By enforcing strict adherence to output formats, Outlines significantly reduces the likelihood of generating incorrect or malformed outputs, thus enhancing the reliability of data-driven applications. Structured Data Generation: The ability to generate structured outputs such as JSON objects simplifies data integration processes for applications like API development, making it easier for developers to work with LLM-generated data. Reduction of Hallucinations: Outlines mitigates the risks associated with hallucinations—erroneous information generated by LLMs—by introducing deterministic generation methods, fostering trust in AI outputs. Ease of Implementation: The library is designed for seamless integration with popular machine learning frameworks, enhancing accessibility for developers and researchers in the NLP field. Caveats: While Outlines presents numerous advantages, it is essential to acknowledge certain limitations. The library’s effectiveness hinges on the design of the underlying model; poorly trained models may still produce suboptimal results despite the constraints imposed by Outlines. Moreover, the requirement for pre-defined output formats may limit flexibility in more dynamic applications. Future Implications of AI Developments The advancements in structured language model generation herald a transformative era for Natural Language Understanding (NLU) and Language Understanding (LU). As AI technologies evolve, we anticipate increasingly sophisticated models capable of generating contextually relevant and structured outputs with minimal supervision. The integration of deterministic output generation will likely lead to enhanced user experiences across various applications, from customer support automation to dynamic content generation. Additionally, as the demand for reliable AI-driven solutions continues to grow, the role of tools like Outlines will be pivotal in bridging the gap between human language and machine understanding. Conclusion The advent of the Outlines library represents a significant milestone in the quest for reliable structured outputs from LLMs. By addressing fundamental challenges associated with output generation, Outlines empowers Natural Language Understanding scientists and developers alike to harness the full potential of AI technologies. As we move forward, the implications of these developments will undoubtedly reshape the landscape of NLU, fostering innovations that enhance the interplay between humans and machines. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context of Lithium Recovery in Electric Vehicle Batteries In recent years, the exponential growth of the electric vehicle (EV) market has necessitated the development of innovative recycling techniques to manage the growing volume of used batteries. A significant breakthrough has emerged from Japan, where researchers have devised a new methodology to recover as much as 90% of lithium from discarded EV batteries. This advancement not only addresses the pressing issue of battery waste but also aligns with global sustainability efforts, particularly on significant occasions such as Earth Day. By implementing this recovery technique at scale, we could witness transformative changes in how EV batteries are manufactured and reused. A Novel Approach to Lithium Extraction The pioneering method developed by Japanese scientists utilizes a unique chemical process that enhances lithium recovery rates substantially compared to traditional recycling techniques, which typically yield less than 50% of the lithium. Central to this innovative approach is the substitution of standard sodium hydroxide with lithium hydroxide, a critical adjustment that facilitates the conversion of battery waste—commonly referred to as ‘black mass’—into high-purity lithium suitable for reuse in new battery production. This process exemplifies a significant technological leap, underscoring the potential for improved resource management within the burgeoning EV industry. Main Goal and Achievability The primary objective of this development is to create a sustainable and efficient framework for lithium recovery that not only meets the rising demand for EV batteries but also minimizes environmental impact. Achieving this goal requires the widespread adoption of the new recycling methodology, coupled with enhancements in collection infrastructure to ensure that a greater proportion of used lithium-ion batteries enter official recycling systems. Currently, only approximately 14% of such batteries are recycled in Japan, highlighting the need for significant improvements in collection and processing mechanisms. Advantages of Enhanced Lithium Recovery Techniques The advantages of this new lithium recovery method are multifaceted: 1. **High Recovery Rates**: The ability to recover up to 90% of lithium substantially exceeds traditional methods, which often achieve less than 50% recovery. 2. **Environmental Benefits**: The process is projected to reduce carbon emissions by approximately 40% compared to conventional recycling techniques, thereby contributing to global sustainability efforts. 3. **Economic Security**: By reducing reliance on imported lithium and increasing domestic recovery capabilities, Japan can stabilize its supply chains and enhance economic resilience in the face of fluctuating global mineral markets. 4. **Resource Efficiency**: The conversion of black mass into high-purity lithium not only minimizes waste but also maximizes resource utilization, supporting a circular economy in the battery sector. 5. **Scalability Potential**: With planned expansions in production capabilities by 2027, this innovative process has the potential to extract tens of thousands of tons of lithium annually by 2035, creating a significant impact on both local and global scales. While these advantages are promising, the implementation of such a system is not without challenges. The current low recycling rate indicates that substantial investments in collection infrastructure and public awareness campaigns are essential to facilitate the transition. Future Implications: The Role of AI in Lithium Recovery Looking ahead, the integration of artificial intelligence (AI) technologies in the lithium recovery process presents exciting possibilities. AI can enhance operational efficiencies by optimizing the sorting and processing of used batteries, predicting maintenance needs, and improving the overall management of recycling facilities. Furthermore, data analytics can provide insights into consumer behavior and battery usage patterns, informing strategies to increase battery collection rates. As AI continues to evolve, its applications in lithium recovery could further streamline the recycling process, reduce costs, and enhance the sustainability of the EV battery lifecycle. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview of Attention Profiling in Generative AI The evolution of Generative AI has brought forth significant advancements, particularly in the realm of neural network architectures like Transformers. One of the pivotal components of these architectures is the attention mechanism, known for its capacity to model dependencies between inputs irrespective of their distance in the data. The ongoing series titled “Profiling in PyTorch” elucidates the importance of understanding profiling traces and tables, which serve as critical tools for optimizing the performance of deep learning models. This analysis centers on enhancing familiarity with profiling techniques, enabling data scientists and machine learning engineers to make informed decisions about the performance of their models. In previous parts of the series, foundational operations within PyTorch were profiled, revealing insights into algorithmic hotspots and their execution timelines. The current focus shifts to attention mechanisms, which, despite their quadratic-time complexity, can be optimized through various strategies. Main Goals and Achievements The primary objective of the original post is to provide a comprehensive understanding of profiling attention mechanisms within the context of PyTorch, specifically focusing on attention algorithms used in Generative AI models. Achieving this goal involves: Demonstrating how to read and interpret profiler traces to identify performance bottlenecks. Exploring various implementations of attention, such as naive attention and scalable dot-product attention, and their corresponding performance characteristics. Encouraging the application of profiling techniques to improve model efficiency, particularly in large-scale Generative AI applications. Advantages of Profiling Attention Mechanisms The original content highlights several advantages associated with profiling attention mechanisms in Generative AI: Performance Optimization: Profiling allows data scientists to pinpoint specific operations that consume excessive time and resources, enabling targeted optimizations. For instance, the transition from an out-of-place to an in-place operation in the naive attention implementation reduced kernel launches and improved execution speed. Understanding Computational Complexity: By profiling various attention implementations, one gains insight into the computational complexity associated with different algorithms, facilitating better design choices for model architectures. Enhanced Model Efficiency: The identification of redundant operations (e.g., unnecessary memory copies) leads to more efficient memory usage and faster execution times, crucial for large-scale models operating on extensive datasets. Scalability Insights: Profiling provides clarity on how models scale with increased input sizes, which is essential in Generative AI applications that often handle large sequences of data. However, it is important to note that profiling results can vary significantly based on hardware configurations, the size of datasets, and the specific implementations of algorithms used. Thus, while profiling serves as a valuable tool for optimization, its findings must be contextualized within the specific operational environment. Future Implications of AI Developments on Profiling Attention Mechanisms As Generative AI continues to evolve, the implications for profiling attention mechanisms are substantial. Future advancements in AI architectures may lead to more complex models, necessitating even more sophisticated profiling techniques to ensure optimal performance. Here are a few anticipated trends: Integration of Automated Profiling Tools: The development of AI-driven tools that can automatically suggest optimizations based on profiling data will enhance the efficiency of model development cycles. Real-Time Profiling: As real-time applications become more prevalent, the need for immediate profiling and optimization during model training and inference will increase, pushing the boundaries of existing profiling technologies. Cross-Architecture Profiling: With the rise of diverse computational architectures (e.g., FPGAs, TPUs), there will be a greater emphasis on profiling techniques that can adapt across different hardware platforms to maximize performance. In summary, as the field of Generative AI progresses, mastering profiling techniques will become increasingly essential for data scientists and engineers striving to develop efficient, scalable models capable of meeting the demands of modern applications. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here