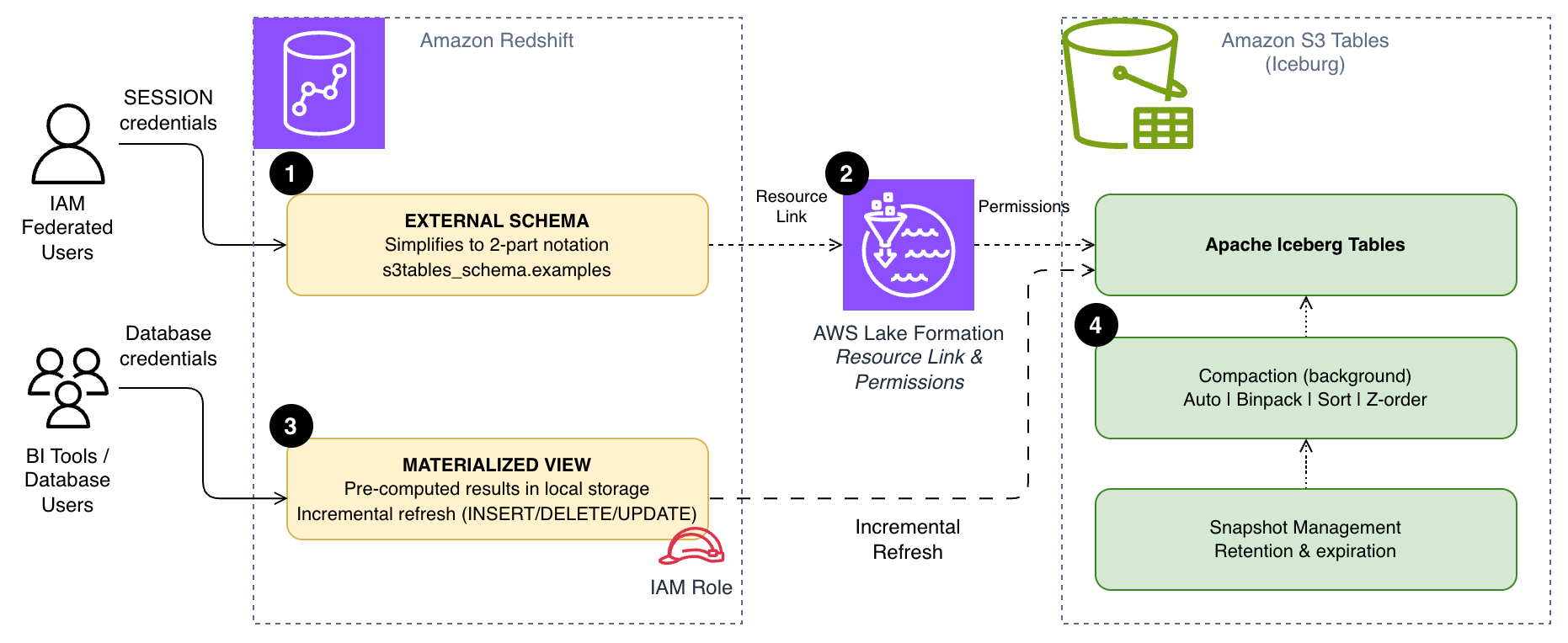
The integration of Amazon S3 Tables and Amazon Redshift presents a robust framework for executing analytical workloads, particularly when utilizing Apache Iceberg tables. As query volumes surge, inefficiencies can become magnified, particularly evident in scenarios involving recurrent queries. These include frequent dashboard refreshes or repetitive data joins executed by analysts throughout the day, which necessitate scanning data directly from Amazon Simple Storage Service (Amazon S3) each time. Furthermore, reliance on fully qualified three-part table references ([email protected]) can introduce unnecessary complexity, complicating interactions for business intelligence (BI) tools and end users accustomed to more straightforward SQL syntax. Additionally, without appropriate data file organization in S3 Tables, queries may engage more files than necessary. By addressing these critical areas, one can significantly enhance the speed, simplicity, and cost-effectiveness of S3 Tables queries in Amazon Redshift, facilitating both recurring dashboard functionalities and supporting large-scale ad hoc analyses.
The primary objective of optimizing S3 Tables queries with Amazon Redshift is to enhance performance and usability through three key strategies: simplifying query syntax with external schemas, utilizing materialized views for storing pre-computed results, and implementing compaction strategies that align data file organization with query patterns. Achieving this optimization can lead to improved query execution times, increased accessibility for end-users, and reduced operational costs. By employing these methodologies, organizations can ensure that data retrieval processes are streamlined and more efficient, thus fostering an environment conducive to data-driven decision-making.
Despite the numerous advantages, there are important considerations to note. For instance, while materialized views provide speed advantages, they also require thoughtful management to avoid excessive storage costs. It is essential to balance the frequency of materialized view refreshes with the costs associated with storing pre-computed data. Additionally, the effectiveness of compaction strategies may vary based on the specific patterns of query access, necessitating careful monitoring and potential adjustments over time.
The landscape of data engineering is poised for significant transformation, particularly with the rise of artificial intelligence (AI). As AI technologies continue to evolve, they will likely enhance the capabilities of data processing and analytics platforms, making them more intelligent and adaptive. For instance, AI-driven optimization algorithms could automate the selection of compaction strategies based on real-time query patterns, further enhancing performance without manual intervention. Additionally, machine learning could be employed to predict query loads and optimize resource allocation dynamically, ensuring that data retrieval processes are not only efficient but also scalable. As these technologies develop, they will undoubtedly shape the future of data engineering, offering new avenues for efficiency and insight extraction from vast datasets.
Disclaimer
The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly.
Source link :


