
Context: Recent Developments in Large Language Models (LLMs) The landscape of Large Language Models (LLMs) has experienced significant transformations over the past six months, particularly marked by the November 2025 inflection point, which heralded substantial advancements in model capabilities, especially in coding tasks. This period has seen a dynamic interchange of the title of the “best” model among prominent AI providers, including OpenAI, Anthropic, and Google, reflecting a rapidly evolving competitive environment. The introduction of innovative coding agents that leverage reinforcement learning has notably improved the practical applications of these models in software development, presenting new opportunities and challenges for data engineers and analysts. Main Goal of Advancements in LLMs The primary objective of these advancements in LLM technology is to enhance the efficiency and accuracy of coding processes, thereby transforming how software development is approached. By leveraging the capabilities of advanced LLMs, data engineers can automate routine coding tasks, reduce errors, and improve productivity. Achieving this involves integrating these models into existing workflows and continuously refining their training through user feedback and real-world application scenarios. Structured List of Advantages Enhanced Coding Accuracy: Recent models exhibit significantly improved accuracy in generating code, as evidenced by successful implementations in complex coding scenarios. Increased Productivity: The automation of simple and repetitive coding tasks allows engineers to focus on more complex and creative aspects of software development. Rapid Model Development: The competitive nature of AI providers has led to accelerated innovation, resulting in models that are not only more powerful but also faster and more efficient. Accessibility of Powerful Models: The emergence of models that can run on standard laptops democratizes access to advanced AI tools, allowing smaller teams to leverage powerful technology without significant investment in infrastructure. Continuous Improvement: The iterative development process of these models ensures that they are constantly evolving based on user experiences and feedback, leading to better performance over time. However, it is essential to acknowledge certain caveats, such as the potential for models to produce incorrect outputs or the need for substantial computational resources for training and deployment. Additionally, the reliance on AI may introduce new challenges related to code quality and maintainability. Future Implications of AI Developments in Data Analytics and Insights The ongoing advancements in AI and LLMs are poised to have profound implications for the field of data analytics and insights. As these models become more sophisticated, they will facilitate more complex data analysis tasks, enabling data engineers to derive insights faster and with greater accuracy. The integration of AI into data workflows could lead to a paradigm shift where data engineers not only focus on data management and processing but also on strategic decision-making based on AI-driven insights. Furthermore, the growing capabilities of local models suggest that organizations will increasingly rely on in-house solutions, potentially reducing the need for cloud-based resources and enhancing data security. In conclusion, the developments in LLMs over the past six months represent a significant leap forward for the data analytics industry. As these technologies continue to evolve, data engineers must remain adaptable, embracing new tools and methodologies to harness the full potential of AI in their work. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview In the realm of cloud gaming, the convergence of technology and user experience allows players to access high-quality games without the burden of extensive hardware requirements. The recent launch of Subnautica 2 on GeForce NOW exemplifies this trend, offering a seamless transition into a captivating alien ocean environment. This integration of cloud gaming platforms signifies a transformative shift, enabling users to engage with new titles concurrently with their official release. Notably, the introduction of 11 new games this week, including limited-time events such as the HITMAN World of Assassination rewards, further emphasizes GeForce NOW’s commitment to enhancing gaming accessibility across various devices. Main Objective and Its Achievement The primary objective of the current trend in cloud gaming is to democratize access to gaming experiences by eliminating the need for high-end hardware and lengthy installations. This goal can be achieved through the implementation of robust cloud infrastructure, which facilitates instant access to games with high fidelity and minimal latency. By leveraging such technologies, platforms like GeForce NOW enable users to engage with their favorite titles immediately, thus enhancing user satisfaction and retention. Advantages of Cloud Gaming Platforms Accessibility: Cloud gaming platforms allow players to access games from multiple devices, including smartphones, tablets, and low-spec PCs. This flexibility broadens the audience for gaming titles, particularly for those without access to expensive hardware. Instant Play: Players can dive straight into games without waiting for downloads or updates, significantly enhancing user experience and engagement rates. Cost-Effectiveness: Users can enjoy high-end gaming experiences without the associated costs of purchasing and maintaining advanced hardware. This model encourages a more extensive user base, as seen with the diverse offerings on GeForce NOW. Regular Updates: Cloud platforms often provide automatic game updates, ensuring that players always have access to the latest features and improvements without manual intervention. Despite these advantages, it is crucial to acknowledge potential limitations, such as internet connectivity requirements and varying performance based on bandwidth. These factors can impact the overall gaming experience, particularly in regions with less reliable internet infrastructure. Future Implications of AI in Cloud Gaming As technological advancements continue to evolve, the integration of Artificial Intelligence (AI) within cloud gaming platforms is poised to redefine user interactions and gaming experiences. Future developments may include personalized gaming environments tailored to individual preferences, enhanced matchmaking algorithms, and improved in-game AI behaviors that adapt to player styles. Such innovations are likely to foster greater immersion and engagement, further solidifying the role of cloud gaming in the broader gaming ecosystem. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context of AI and Data Sovereignty In contemporary discussions surrounding artificial intelligence (AI) and its integration into business frameworks, the concept of data sovereignty has gained significant traction. As Kevin Dallas, CEO of EDB, asserts, “Data is really a new currency; it’s the IP for many companies.” This sentiment encapsulates growing concerns among enterprises regarding the safeguarding of intellectual property (IP) in the face of deploying AI-enhanced applications reliant on cloud-based large language models. The pivotal questions arise: Are organizations jeopardizing their IP and competitive advantage? The emergence of AI and data sovereignty is driven by the need for companies to assert control over their data and AI systems, moving away from dependency on centralized providers. Internal data from EDB indicates that 70% of global executives recognize the imperative for a sovereign data and AI platform as a requisite for success. The dialogue surrounding AI sovereignty has escalated into a global policy imperative. Industry leaders, such as Jensen Huang, CEO of NVIDIA, have emphasized the necessity for nations to build their own AI infrastructures, leveraging their unique linguistic and cultural assets to develop and refine AI solutions. This growing movement signals a fundamental shift in how enterprises and nations approach AI development and data management. Main Goal and Achievement Strategies The primary goal articulated in this discourse is to establish AI and data sovereignty, enabling organizations to reclaim control over their data and AI systems. This can be achieved through a multi-faceted approach: 1. **Investing in Localized Infrastructure**: Organizations must prioritize the development of localized AI platforms, diminishing reliance on external cloud providers. 2. **Encouraging Policy Dialogues**: Engaging in conversations at national and international forums can help shape policies that support data sovereignty. 3. **Fostering Collaboration**: Enterprises can collaborate with local governments and technology firms to create a robust ecosystem that supports AI development tailored to specific local needs. By adopting these strategies, organizations can mitigate risks associated with data loss and maintain a competitive edge in their respective markets. Advantages of AI and Data Sovereignty The pursuit of AI and data sovereignty presents numerous advantages, including: 1. **Enhanced Security and Privacy**: Controlling data locally reduces the risks associated with data breaches and unauthorized access, fostering a secure environment for sensitive information. 2. **Intellectual Property Protection**: By managing their data and AI systems, organizations can safeguard their intellectual property more effectively, ensuring that proprietary data remains within their control. 3. **Cultural Relevance**: Developing localized AI solutions allows organizations to create applications that resonate more profoundly with specific cultural and linguistic contexts, enhancing user engagement and satisfaction. 4. **Strategic Independence**: Establishing sovereignty over data and AI systems empowers organizations to make independent decisions without external constraints, thus fostering innovation and agility. However, it is crucial to acknowledge potential limitations, such as the initial costs associated with building localized infrastructures and the need for specialized talent to manage these systems. Future Implications of AI Developments As the landscape of AI continues to evolve, the implications for data sovereignty will become increasingly pronounced. The advent of more sophisticated AI technologies, such as autonomous systems, will necessitate robust frameworks for data governance and control. Future developments may include: 1. **Regulatory Advances**: Governments may introduce stricter regulations to ensure that organizations maintain sovereignty over their data, leading to more stringent compliance requirements. 2. **International Collaboration**: As AI becomes more integral to global economies, international partnerships may emerge to share best practices in data sovereignty, fostering a cooperative approach to AI governance. 3. **Technological Innovations**: Advances in decentralized technologies, such as blockchain, could offer new solutions for maintaining data sovereignty, enabling organizations to secure and manage their data more effectively. In conclusion, as enterprises navigate the complexities of AI integration, the pursuit of data sovereignty will remain a critical priority, shaping the future of AI development and organizational strategy. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction The rapid advancements in artificial intelligence (AI) and machine learning (ML) technologies are reshaping various industries, including Computer Vision and Image Processing. The recent workshop titled “Building with AI 2026” highlighted the potential of utilizing tools like Gemini CLI in conjunction with Model Context Protocol (MCP) to streamline development processes. This blog post explores the implications of these technologies for Vision Scientists, detailing the goals, advantages, and future trends in the field. Main Goal and Achievement The primary goal discussed in the workshop is to enhance the efficiency of deploying AI models in practical applications, specifically in creating bots and applications that can interact with users effectively. This can be achieved by leveraging Gemini CLI, which allows developers to articulate their needs in natural language, thus simplifying the deployment process. By employing MCPs, developers can access Google’s extensive resources without grappling with complex command-line interfaces, enabling a more intuitive experience. Advantages of Using Gemini CLI and MCPs Streamlined Development Process: The integration of Gemini CLI with official MCPs allows for a more cohesive development workflow. Developers can directly access Google’s APIs and resources, reducing the time spent on setup and configuration. Enhanced Accessibility: The natural language interface of Gemini CLI lowers the barrier to entry for new developers. This democratizes access to advanced AI tools, allowing scientists and engineers from various backgrounds to contribute to projects without needing extensive command-line expertise. Official Documentation Access: The Google Developer Knowledge MCP provides verified information directly from official documentation. This minimizes the risks associated with outdated or misleading information encountered during web searches, ensuring that developers are working with the most current data. Reducing Errors: By facilitating a direct line of communication between developers and the tools they use, Gemini CLI enables the identification and resolution of errors in real-time. This iterative feedback loop is crucial for refining AI models and ensuring robust performance. Reproducibility of Results: The structured workflows established by deploying models through Gemini CLI ensure that results can be consistently reproduced. This is particularly important in scientific research, where reproducibility is a cornerstone of valid experimentation. Caveats and Limitations While the advancements presented are promising, it is essential to recognize certain limitations. The reliance on cloud-based services necessitates a stable internet connection and may incur costs associated with API usage and data storage. Additionally, as the tools evolve, ongoing updates and changes in APIs may require developers to adapt their workflows continuously. Future Implications The integration of AI into Computer Vision and Image Processing is expected to accelerate in the coming years. With continuous improvements in tools like Gemini CLI and the growing adoption of MCPs, Vision Scientists will be empowered to create more sophisticated applications that leverage real-time data processing and user interaction. Future iterations of these technologies may further simplify the development process, enabling scientists to focus more on innovative research rather than the complexities of deployment. Conclusion In conclusion, the workshop on Gemini CLI and MCPs illustrates the transformative potential of AI technologies in the realm of Computer Vision and Image Processing. By simplifying development workflows, enhancing accessibility, and ensuring the use of reliable resources, these tools present significant advantages for Vision Scientists. As the technology continues to evolve, it holds the promise of fostering greater innovation and efficiency in the field. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here
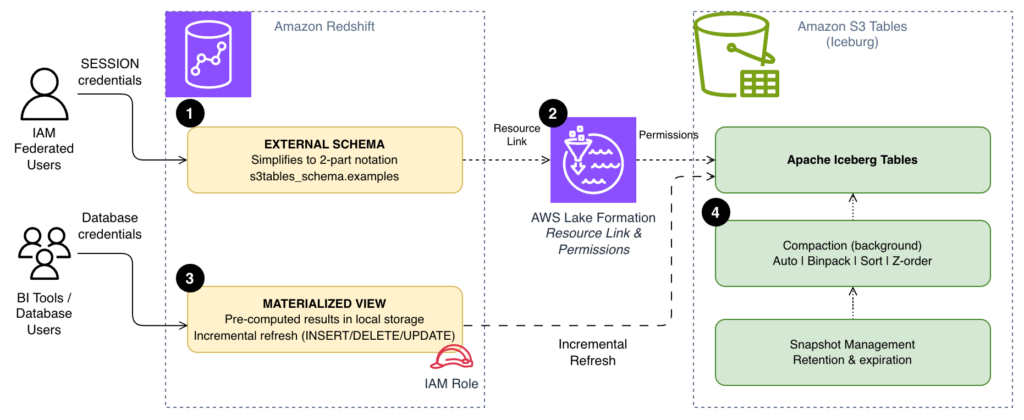
Contextual Overview The integration of Amazon S3 Tables and Amazon Redshift presents a robust framework for executing analytical workloads, particularly when utilizing Apache Iceberg tables. As query volumes surge, inefficiencies can become magnified, particularly evident in scenarios involving recurrent queries. These include frequent dashboard refreshes or repetitive data joins executed by analysts throughout the day, which necessitate scanning data directly from Amazon Simple Storage Service (Amazon S3) each time. Furthermore, reliance on fully qualified three-part table references ([email protected]) can introduce unnecessary complexity, complicating interactions for business intelligence (BI) tools and end users accustomed to more straightforward SQL syntax. Additionally, without appropriate data file organization in S3 Tables, queries may engage more files than necessary. By addressing these critical areas, one can significantly enhance the speed, simplicity, and cost-effectiveness of S3 Tables queries in Amazon Redshift, facilitating both recurring dashboard functionalities and supporting large-scale ad hoc analyses. Main Goal and Achievable Outcomes The primary objective of optimizing S3 Tables queries with Amazon Redshift is to enhance performance and usability through three key strategies: simplifying query syntax with external schemas, utilizing materialized views for storing pre-computed results, and implementing compaction strategies that align data file organization with query patterns. Achieving this optimization can lead to improved query execution times, increased accessibility for end-users, and reduced operational costs. By employing these methodologies, organizations can ensure that data retrieval processes are streamlined and more efficient, thus fostering an environment conducive to data-driven decision-making. Advantages of Optimization Simplified Query Syntax: By transitioning from three-part to two-part notation via external schemas, query execution becomes less cumbersome for users, particularly in BI tools and application code. Enhanced Performance with Materialized Views: Materialized views allow for the local storage of pre-computed results, significantly reducing the frequency and volume of data scans against S3, which can lead to substantial performance gains. Cost-Efficiency Through Compaction: Configuring compaction strategies to fit specific query patterns minimizes the number of files read during queries, thereby optimizing resource utilization and potentially lowering associated costs. Incremental Refresh Capabilities: Redshift’s support for incremental refresh of materialized views enables handling of large datasets efficiently, as only changed rows are processed, reducing both time and computational expenses. Limitations and Caveats Despite the numerous advantages, there are important considerations to note. For instance, while materialized views provide speed advantages, they also require thoughtful management to avoid excessive storage costs. It is essential to balance the frequency of materialized view refreshes with the costs associated with storing pre-computed data. Additionally, the effectiveness of compaction strategies may vary based on the specific patterns of query access, necessitating careful monitoring and potential adjustments over time. Future Implications The landscape of data engineering is poised for significant transformation, particularly with the rise of artificial intelligence (AI). As AI technologies continue to evolve, they will likely enhance the capabilities of data processing and analytics platforms, making them more intelligent and adaptive. For instance, AI-driven optimization algorithms could automate the selection of compaction strategies based on real-time query patterns, further enhancing performance without manual intervention. Additionally, machine learning could be employed to predict query loads and optimize resource allocation dynamically, ensuring that data retrieval processes are not only efficient but also scalable. As these technologies develop, they will undoubtedly shape the future of data engineering, offering new avenues for efficiency and insight extraction from vast datasets. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview The Māui dolphin, characterized by its small size and distinctive rounded dorsal fin, represents one of the rarest and most endangered marine mammal species, with a critically low known population of merely 54 individuals. This sub-species has faced severe threats due to detrimental fishing practices, particularly gillnetting along the west coast of New Zealand, leading to its precarious status. Recent advancements in technology, particularly the integration of artificial intelligence (AI) and drone technology, are being harnessed by scientists and conservationists to gather essential data about these elusive creatures. The strategic application of these technologies not only targets the preservation of the Māui dolphin but also exemplifies a broader trend in environmental conservation efforts aimed at utilizing AI and machine learning (ML) to combat species extinction. Main Goals and Achievements The primary objective of the collaborative efforts led by the not-for-profit organization MAUI63 is to enhance the understanding and conservation of the Māui dolphin population. This goal is pursued through the development and deployment of AI-powered drones capable of efficiently locating, tracking, and identifying individual dolphins. By leveraging machine learning algorithms and high-resolution imaging, the initiative aims to provide robust data that can inform conservation strategies and decision-making processes. Furthermore, the integration of cloud computing services facilitates the storage, analysis, and sharing of vital ecological data. Advantages of AI and Drone Technology in Conservation Increased Data Collection Efficiency: AI-driven drones significantly enhance the scale and speed of data collection compared to traditional monitoring methods. For instance, the MAUI63 team successfully identified dolphins in real-time from a distance of 16 kilometers, demonstrating the technological capability to cover large marine areas rapidly. Improved Identification Accuracy: The unique rounded dorsal fins of Māui dolphins present challenges for conventional identification methods. However, the development of specialized computer vision models allows for precise identification that overcomes the limitations of human observation. Real-time Monitoring and Reporting: The integration of AI and cloud computing enables the creation of applications, such as the Sea Spotter app, which allows for the immediate upload and analysis of dolphin sightings, enhancing community involvement in conservation efforts. Data-Driven Conservation Strategies: The collection of scientifically robust data facilitates evidence-based decision-making among conservation stakeholders, which is crucial for effective policy formulation and habitat protection. Collaboration with Fishing Industries: By working directly with fishing companies, there is potential to minimize bycatch incidents, thereby protecting the Māui dolphins from fishing-related threats. Future Implications The implications of utilizing AI and drone technology in conservation are profound, suggesting a transformative shift in how species monitoring and protection are approached. As machine learning techniques continue to evolve, their applications in wildlife conservation are expected to expand, potentially encompassing a wider array of endangered species. Future projects may include more comprehensive ecological monitoring systems that integrate various data sources, such as environmental sensors and satellite imagery. This technological synergy could lead to enhanced predictive modeling capabilities, thereby enabling proactive conservation measures. Moreover, as the methodologies developed for the Māui dolphin project prove successful, they may serve as templates for global conservation initiatives, potentially influencing policy at international levels. Conclusion The integration of AI and drone technology in studying and conserving the Māui dolphin illustrates the potential of modern technology to address critical environmental challenges. While this initiative is still in its early stages, the promising results underscore the importance of collaborative efforts in leveraging technology for conservation purposes. By continuing to refine these techniques and expanding their application to other species, the conservation community can enhance its capacity to combat extinction effectively. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Introduction In the realm of data science, the transition from theoretical frameworks to practical applications often reveals a stark contrast: the neatly packaged data in textbooks is seldom encountered in real-world scenarios. The unpredictability of messy data—characterized by outliers, skewed distributions, and significant variances—poses a considerable challenge for practitioners. This phenomenon is particularly relevant in the fields of Natural Language Understanding (NLU) and Language Understanding (LU), where the intricacies of human language can lead to data that defies traditional analytical assumptions. To address these challenges, robust statistical methods emerge as essential tools within the data scientist’s arsenal. Robust statistics are designed to yield valid and reliable results even when data conditions are less than ideal. This article will explore the application of robust statistical techniques for NLU and LU professionals, emphasizing the importance of adapting methodologies to the realities of messy data. Main Goal and Achieving Robustness in Data Science The principal objective of employing robust statistical techniques is to enhance the reliability of findings derived from complex datasets. In scenarios where traditional statistical assumptions—such as normality and homoscedasticity—are violated, robust methods offer alternative pathways to valid conclusions. For NLU scientists, this translates into the ability to derive insights from linguistic data that may be noisy or unstructured, ensuring that the outcomes are not disproportionately influenced by outliers or skewed distributions. This can be achieved by utilizing statistical tests that do not rely on stringent assumptions about the data’s distribution. For instance, methods like the Mann-Whitney U test, Wilcoxon Signed-Rank Test, and Welch’s ANOVA provide robust alternatives that facilitate meaningful comparisons and analyses even in the presence of messy data. By adopting these techniques, data scientists can maintain the integrity of their analyses and derive actionable insights from real-world datasets. Advantages of Robust Statistical Techniques Increased Validity: Robust methods yield conclusions that are less sensitive to outliers and data anomalies. This leads to findings that can be trusted even when faced with non-normal distributions. Adaptability: These techniques can be applied across various scenarios in NLU and LU, from comparing different text corpora to analyzing sentiment scores, thereby making them versatile tools for data scientists. Enhanced Interpretability: By focusing on ranks or medians rather than means, robust statistics often provide clearer insights into the data’s underlying patterns, which is crucial for understanding complex linguistic phenomena. Mitigation of Assumption Violations: Robust methods allow for analyses in situations where traditional assumptions are untenable, thus broadening the scope of possible analyses that data scientists can perform. However, it is important to acknowledge certain limitations. While robust statistical methods reduce the influence of outliers, they do not eliminate the necessity for data cleaning and preprocessing. Additionally, the interpretation of results from robust tests may differ from classical methods, necessitating a careful approach to communicating findings. Future Implications in AI and NLU The evolution of artificial intelligence, particularly in natural language processing, promises to further impact the methodologies employed by NLU scientists. As machine learning models become increasingly sophisticated, they may incorporate robust statistical techniques inherently within their algorithms, facilitating more accurate interpretations of linguistic data. Moreover, advancements in AI will likely lead to the development of tools that can automatically detect and address data anomalies, thus streamlining the analysis process for data scientists. As the complexity of datasets continues to increase, the integration of robust statistical approaches will become even more critical. NLU scientists must remain vigilant and adaptable, embracing these methodologies to ensure that their analyses remain relevant and impactful in a rapidly evolving landscape. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Context and Overview As we advance into 2026, the landscape of large language models (LLMs) is evolving beyond mere scale. The research community is increasingly focused on enhancing the safety, controllability, and utility of these models as they function as real-world agents. This shift highlights critical themes such as the assessment of persuasion risks, the integration of harmful-content mechanisms, and the development of agent privacy protocols. The research papers produced during this year reflect significant strides in these areas, offering insights that are crucial for AI researchers, data scientists, and developers operating in Generative AI (GenAI) domains. Main Goal of Research The primary objective of the leading research papers in LLMs for 2026 is to determine whether AI systems can be designed to be controllable, interpretable, secure, and effective in real-world applications. By addressing these questions, researchers aim to build systems that not only perform tasks but also operate safely within human environments. This goal can be achieved through an emphasis on rigorous evaluation frameworks, improved model architectures, and innovative methodologies that facilitate better human-AI interaction. Advantages and Evidence Improved Safety and Control: The studies underscore the necessity of creating frameworks for evaluating AI manipulation risks, as demonstrated by research from Google DeepMind, which tested models for manipulative behaviors across diverse domains. Enhanced Usability: Research like the “AI Co-Mathematician” illustrates how LLMs can support complex tasks such as mathematical discovery, thus broadening their applicability in research and practical scenarios. Robust Evaluation Techniques: Papers introducing benchmarks like “SteerEval” provide structured methodologies for assessing how well LLMs adhere to steering instructions, which is vital for ensuring their reliability in sensitive contexts. Addressing Security Concerns: The exploration of invisible Unicode instruction injections highlights the importance of understanding vulnerabilities within AI systems, guiding the development of more secure AI models. Facilitating Temporal Reasoning: The introduction of frameworks such as “AdapTime” signals advancements in how LLMs can handle time-sensitive questions, enhancing their functionality in dynamic environments. Future Implications The trajectory of AI development, particularly in the realm of LLMs, indicates a profound impact on various sectors, including data analytics. As models become more sophisticated in their reasoning and interaction capabilities, data engineers will find opportunities to leverage these advancements to improve data processing and insights generation. Furthermore, as ethical and safety considerations become more prominent, the demand for transparent and interpretable AI systems will grow, thereby necessitating continuous research and development in these areas. Future LLMs may not only act as tools for automation but will also evolve into collaborative entities that enhance human decision-making processes, thus reshaping the landscape of data analytics and insights. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview of Operationalizing AI The integration of Artificial Intelligence (AI) into various sectors has become a focal point for enhancing operational efficiency and achieving strategic sovereignty. The concept of “Operationalizing AI for Scale and Sovereignty” emphasizes the necessity for organizations, especially those within governmental and enterprise frameworks, to establish robust, secure, and scalable AI capabilities. Thought leaders in this domain, such as Chris Davidson from Hewlett Packard Enterprise and Arjun Shankar from Oak Ridge National Laboratory, play pivotal roles in shaping the discourse around AI’s operationalization. Their contributions highlight the intersection of high-performance computing (HPC), data science, and AI, underscoring the collaborative efforts required to advance these technologies. Main Goals of Operationalizing AI The primary objective of operationalizing AI is to create a framework that enables organizations to leverage AI technologies effectively and responsibly. Achieving this goal involves implementing AI Factory solutions and Sovereign AI initiatives that facilitate secure data handling, compliance with regulations, and alignment with national interests. By fostering partnerships among governments, enterprises, and research institutions, organizations can create a synergistic environment conducive to innovation and scalability in AI applications. Advantages of Operationalizing AI Enhanced Scalability: The establishment of scalable AI capabilities allows organizations to manage and process larger datasets efficiently. This scalability is critical for applications requiring real-time data analysis and decision-making. Improved Security: Sovereign AI initiatives prioritize data security and compliance, ensuring that sensitive information is protected against breaches. This aspect is crucial for organizations handling confidential government or proprietary data. Interdisciplinary Collaboration: The bridging of computer science and data science fosters cross-disciplinary partnerships, enabling comprehensive scientific discovery campaigns. This collaboration is essential for tackling complex challenges in AI research. Optimized Performance: By leveraging high-performance computing resources, organizations can conduct large-model training and deploy AI solutions at an unprecedented pace and efficiency, positioning them at the forefront of technological advancement. Limitations and Considerations While the advantages of operationalizing AI are significant, organizations must also navigate certain caveats. The complexity of integrating AI systems into existing infrastructures can pose challenges, including potential resistance to change within organizational cultures. Furthermore, the rapid evolution of AI technologies necessitates ongoing investment in training and development to ensure that personnel are equipped to handle sophisticated AI tools and frameworks. Future Implications of AI Developments As AI technologies continue to evolve, their implications for operational efficiency and societal governance will deepen. The ongoing advancements in AI capabilities promise to revolutionize industries by enhancing automation, improving predictive analytics, and driving innovation in data-driven decision-making. Organizations that successfully operationalize AI will likely gain competitive advantages, positioning themselves as leaders in their respective fields. However, the ethical considerations surrounding AI deployment will necessitate vigilant oversight and governance to ensure that AI serves the public good while advancing technological frontiers. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here

Contextual Overview of Holography in Computer Vision The concept of holography, once relegated to the realms of science fiction, has begun to manifest itself in tangible applications that promise to revolutionize the fields of computer vision and image processing. Pioneering efforts in this domain are exemplified by the work of Shawn Frayne, co-founder and CEO of Looking Glass Factory. With over two decades of dedication, Frayne has successfully developed holographic displays that facilitate immersive experiences without the necessity of headgear or dark environments. This breakthrough technology allows multiple users to engage with three-dimensional holographic content in a shared space, thus democratizing access to advanced visualizations. Main Goal and Achievement Pathways The primary objective of this technological advancement is to create a seamless interface for interacting with 3D holograms, thereby enhancing user engagement and understanding. This is particularly relevant to professionals in the fields of computer vision and image processing, as it enables richer data interpretation and presentation. Achieving this goal requires ongoing collaboration among experts in computer vision, artificial intelligence, and display technologies, as well as active participation in forums like OSCCA, where thought leaders converge to discuss innovations and their implications. Advantages of Holographic Displays Enhanced User Interaction: Holographic displays permit multiple viewers to interact with 3D content simultaneously, fostering collaborative environments that are critical in research and education. Elimination of Physical Barriers: The absence of glasses or headgear eliminates discomfort and allows for spontaneous engagement, making the technology more accessible to a broader audience. Integration of AI and Computer Vision: The convergence of AI with holographic technology enables real-time processing of visual data, which can significantly enhance the capabilities of computer vision applications. Innovative Communication Tools: This technology serves as a powerful medium for presenting complex data sets in a more intuitive manner, facilitating better understanding and retention among users. However, it is crucial to acknowledge certain limitations associated with this technology. The initial cost of implementation and the need for specialized content creation tools may pose barriers to widespread adoption. Additionally, as with any emerging technology, continuous advancements are necessary to keep pace with user expectations and application requirements. Future Implications of AI in Holography The future of holographic technology in conjunction with artificial intelligence holds significant promise. As AI algorithms become more sophisticated, they will enhance the interactivity and realism of holographic displays, enabling predictive analytics and deeper insights into visual data. The anticipated developments in this sphere are likely to catalyze advancements in various applications, including medical imaging, education, and industrial design. Vision scientists and researchers will find themselves at the forefront of this evolution, leveraging these tools to push the boundaries of what is possible in visual representation and interpretation. Disclaimer The content on this site is generated using AI technology that analyzes publicly available blog posts to extract and present key takeaways. We do not own, endorse, or claim intellectual property rights to the original blog content. Full credit is given to original authors and sources where applicable. Our summaries are intended solely for informational and educational purposes, offering AI-generated insights in a condensed format. They are not meant to substitute or replicate the full context of the original material. If you are a content owner and wish to request changes or removal, please contact us directly. Source link : Click Here